This is an introductory tutorial on using Theano, the Python library. I’m going to start from scratch and assume no previous knowledge of Theano. However, understanding how neural networks work will be useful when getting to the code examples towards the end.
The plan for the tutorial is as follows:
- Give a basic introduction to Theano and explain the important concepts.
- Go over the main operations that we have available in Theano.
- Look at working code examples.
I recently gave this tutorial as a talk in University of Cambridge and it turned out to be way more popular than expected. In order to give more people access to the material, I’m now writing it up as a blog post.
I do not claim to know everything about Theano, and I constantly learn new things myself. If you find any errors or have suggestions on how to improve this tutorial, do let me know.
The code examples can be found in the Github repository: https://github.com/marekrei/theano-tutorial
1. What is Theano?

Theano is a Python library for efficiently handling mathematical expressions involving multi-dimensional arrays (also known as tensors). It is a common choice for implementing neural network models. Theano has been developed in University of Montreal, in a group led by Yoshua Bengio, since 2008.
Some of the features include:
- automatic differentiation – you only have to implement the forward (prediction) part of the model, and Theano will automatically figure out how to calculate the gradients at various points, allowing you to perform gradient descent for model training.
- transparent use of a GPU – you can write the same code and run it either on CPU or GPU. More specifically, Theano will figure out which parts of the computation should be moved to the GPU.
- speed and stability optimisations – Theano will internally reorganise and optimise your computations, in order to make them run faster and be more numerically stable. It will also try to compile some operations into C code, in order to speed up the computation.
Technically, Theano isn’t actually a machine learning library, as it doesn’t provide you with pre-built models that you can train on your dataset. Instead, it is a mathematical library that provides you with tools to build your own machine learning models. But if you are looking for machine learning toolkits, there are several good ones implemented on top of Theano:
- Blocks http://blocks.readthedocs.org/en/latest/
- Keras http://keras.io/
- Lasagne http://lasagne.readthedocs.org/en/latest/
- PyLearn2 http://deeplearning.net/software/pylearn2/
2. Python refresher
Theano is a Python library, so let’s go over some important points in Python.
- Python is an interpreted language, which makes it more platform independent but generally slower than C, for example.
- Python uses dynamic typing. While each variable does have a specific type during execution, these are not explicitly stated in the code.
- Python uses indentation for block delimiting. So where C or Java would use curly brackets to separate a block, Python uses whitespace. Here we define a function f to take parameter x and return 2*x:
def f(x): return 2*x - We define a list in Python with square brackets:
a = [1,2,3,4,5] a[1] == 2
- We define a dictionary (key-value mapping) with curly brackets:
b = {'key1': 1, 'key2':2} b['key2'] == 2 - List comprehension is a neat shorthand in Python for constructing lists. Here we loop for 5 steps (values 0-4), and each time add i+1 to the list:
c = [i+1 for i in range(5)] c[1] == 2
3. Using Theano
In order to use Theano, you will need to install the dependencies and install Theano itself. If you’re using Ubuntu (tested for 14.04), you might get away with just running these two commands:
sudo apt-get install python-numpy python-scipy python-dev python-pip python-nose g++ libopenblas-dev git sudo pip install Theano
If that doesn’t work for you, take a look at the original Theano homepage, which contains instructions for various platforms:
http://deeplearning.net/software/theano/install.html
To use Theano in your Python script, include it using:
import theano
4. Minimal Working Example
Here is the smallest example I could come up with, which uses Theano and actually does something:
import theano
import numpy
x = theano.tensor.fvector('x')
W = theano.shared(numpy.asarray([0.2, 0.7]), 'W')
y = (x * W).sum()
f = theano.function([x], y)
output = f([1.0, 1.0])
print output
So what’s happening here?
We first define a Theano variable x to be a vector of 32-bit floats, and give it name ‘x’:
x = theano.tensor.fvector('x')
Next, we create a Theano variable W, assign its value to be vector [0.2, 0.7], and name it ‘W’:
W = theano.shared(numpy.asarray([0.2, 0.7]), 'W')
We define y to be the sum of all elements in the element-wise multiplication of x and W:
y = (x * W).sum()
We define a Theano function f, which takes as input x and outputs y:
f = theano.function([x], y)
Then call this function, giving as the argument vector [1.0, 1.0], essentially setting the value of variable x:
output = f([1.0, 1.0])
The script prints out the summed product of [0.2, 0.7] and [1.0, 1.0], which is:
0.2*1.0 + 0.7*1.0 = 0.9
Don’t worry if the code doesn’t fully make sense. We’ll go over the important parts in more detail.
5. Symbolic graphs in Theano (!)
I’d say this section contains the most crucial part to understanding Theano.
When we are creating a model with Theano, we first define a symbolic graph of all variables and operations that need to be performed. And then we can apply this graph on specific inputs to get outputs.
For example, what do you think happens when this line of Theano code is executed in our script?
y = (x * W).sum()
The system takes x and W, multiplies them together and sums the values. Right?
NOPE
Instead, we create a Theano object y that knows its values can be calculated as the dot-product of x and W. But the required mathematical operations are not performed here. In fact, when this line was executed in our example code above, x didn’t even have a value yet.
By chaining up various operations, we are creating a graph of all the variables and functions that need to be used to reach the output values. This symbolic graph is also the reason why we can only use Theano-specific operations when defining our models. If we tried to integrate functions from some random Python library into our network, they would attempt to perform the calculations immediately, instead of returning a Theano variable as needed. Exceptions do exist – Theano overrides some basic Python operators to act as expected, and NumPy is quite well integrated with Theano.
6. Variables
We can define variables which don’t have any values yet. Normally, these would be used for inputs to our network.
The variables have to be of a specific type though. For example, here we define variable x to be a vector of 32-bit floats, and give it name ‘x’:
x = theano.tensor.fvector('x')
The names are generally useful for debugging and informative error messages. Theano won’t have access to your Python variable names, so you have to assign explicit Theano names for each variable if you want them to be referred to as something more useful than just “a tensor”.
There are a number of different variable types available, just have a look at the list here. Some of the more popular ones include:
[table width=”500″ colwidth=”100|50|50″ colalign=”left|center|center”]
Constructor, dtype, ndim
fvector,float32,1
ivector,int32,1
fscalar,float32,0
fmatrix,float32,2
ftensor3,float32,3
dtensor3,float64,3
[/table]
You can also define a generic vector (or tensor) and set the type with an argument:
x = theano.tensor.vector('x', dtype=float32)
If you don’t set the dtype, you will create vectors of type config.floatX. This will become relevant in the section about GPUs.
7. Shared variables
We can also define shared variables, which are shared between different functions and different function calls. Normally, these would be used for weights in our neural network. Theano will automatically try to move shared variables to the GPU, provided one is available, in order to speed up computation.
Here we define a shared variable and set its value to [0.2, 0.7].
W = theano.shared(numpy.asarray([0.2, 0.7]), 'W')
The values in shared variables can be accessed and modified outside of our Theano functions using these commands:
W.get_value() W.set_value([0.1, 0.9])
8. Functions
Theano functions are basically hooks for interacting with the symbolic graph. Commonly, we use them for passing input into our network and collecting the resulting output.
Here we define a Theano function f that takes x as input and returns y as output:
f = theano.function([x], y)
The first parameter is the list of input variables, and the second parameter is the list of output variables. Although if there’s only one output variable (like now) we don’t need to make it into a list.
When we construct a function, Theano takes over and performs some of its own magic. It builds the computational graph and optimises it as much as possible. It restructures mathematical operations to make them faster and more stable, compiles some parts to C, moves some tensors to the GPU, etc.
Theano compilation can be controlled by setting the value of mode in the environement variable THEANO_FLAGS:
- FAST_COMPILE – Fast to compile, slow to run. Python implementations only, minimal graph optimisation.
- FAST_RUN – Slow to compile, fast to run. C implementations where available, full range of optimisations
9. Minimal Training Example
Here’s a minimal script for actually training something in Theano. We will be training the weights in W using gradient descent, so that the result from the model would be 20 instead of the original 0.9.
import theano
import numpy
x = theano.tensor.fvector('x')
target = theano.tensor.fscalar('target')
W = theano.shared(numpy.asarray([0.2, 0.7]), 'W')
y = (x * W).sum()
cost = theano.tensor.sqr(target - y)
gradients = theano.tensor.grad(cost, [W])
W_updated = W - (0.1 * gradients[0])
updates = [(W, W_updated)]
f = theano.function([x, target], y, updates=updates)
for i in xrange(10):
output = f([1.0, 1.0], 20.0)
print output
We create a second input variable called target, which will act as the target value we use for training:
target = theano.tensor.fscalar('target')
In order to train the model, we need a cost function. Here we use a simple squared distance from the target:
cost = theano.tensor.sqr(target - y)
Next, we want to calculate the partial gradients for the parameters that will be updated, with respect to the cost function. Luckily, Theano will do that for us. We simply call the grad function, pass in the real-valued cost and a list of all the variables we want gradients for, and it will return a list of those gradients:
gradients = theano.tensor.grad(cost, [W])
Now let’s define a symbolic variable for what the updated version of the parameters will look like. Using gradient descent, the update rule is to subtract the gradient, multiplied by the learning rate:
W_updated = W - (0.1 * gradients[0])
And next we create a list of updates. More specifically, a list of tuples where the first element is the variable we want to update, and the second element is a variable containing the values that we want the first variable to contain after the update. This is just a syntax that Theano requires.
updates = [(W, W_updated)]
Have to define a Theano function again, with a couple of changes:
f = theano.function([x, target], y, updates=updates)
It now takes two input arguments – one for the input vector, and another for the target value used for training. And the list of updates also gets attached to the function as well. Every time this function is called, we pass in values for x and target, get back the value for y as output, and Theano performs all the updates in the update list.
In order to train the parameters, we repeatedly call this function (10 times in this case). Normally, we’d pass in different examples from our training data, but for this example we use the same x=[1.0, 1.0] and target=20 each time:
for i in xrange(10):
output = f([1.0, 1.0], 20.0)
print output
When the script is executed, the output looks like this:
0.9 8.54 13.124 15.8744 17.52464 18.514784 19.1088704 19.46532224 19.679193344 19.8075160064
The first time the function is called, the output value is still 0.9 (like in the previous example), because the updates have not been applied yet. But with each consecutive step, the output value becomes closer and closer to the desired target 20.
10. Useful operations
This covers the basic logic behind building models with Theano. The example was very simple, but we are free to define increasingly complicated networks, as long as we use Theano-specific functions. Now let’s look at some of these building blocks that we have available.
Evaluate the value of a Theano variable
The eval() function forces the Theano variable to calculate and return its actual (numerical) value. If we try to just print the variable a, we only print its name. But if we use eval(), we get the actual square matrix that it is initialised to.
> a = theano.shared(numpy.asarray([[1.0,2.0],[3.0,4.0]]), 'a')
> a
a
> a.eval()
array([[1., 2.],
[3., 4.]])
This eval() function isn’t really used for building models, but it can be useful for debugging and learning how Theano works. In the examples below, I will be using the matrix a and the eval() function to print the value of each variable and demonstrate how different operations work.
Basic element-wise operations: + – * /
c = ((a + a) / 4.0)
array([[ 0.5, 1. ],
[ 1.5, 2. ]])
Dot product
c = theano.tensor.dot(a, a)
array([[ 7., 10.],
[15., 22.]])
Activation functions
c = theano.tensor.nnet.sigmoid(a)
c = theano.tensor.tanh(a)
array([[ 0.76159416, 0.96402758],
[ 0.99505475, 0.9993293 ]])
Softmax (row-wise)
c = theano.tensor.nnet.softmax(a)
array([[ 0.26894142, 0.73105858],
[ 0.26894142, 0.73105858]])
Sum
c = a.sum() c = a.sum(axis=1) array([ 3., 7.])
Max
c = a.max() c = a.max(axis=1) array([ 2., 4.])
Argmax
c = theano.tensor.argmax(a) c = theano.tensor.argmax(a, axis=1) array([1, 1])
Reshape
We sometimes need to change the dimensions of a tensor and reshape() allows us to do that. It takes as input a tuple containing the new shape and returns a new tensor with that shape. In the first example below, we shape a square matrix into a 1×4 matrix. In the second example, we use -1 which means “as big as the dimension needs to be”.
a = theano.shared(numpy.asarray([[1,2],[3,4]]), 'a') c = a.reshape((1,4)) array([[1, 2, 3, 4]]) c = a.reshape((-1,)) array([1, 2, 3, 4])
Zeros-like, ones-like
These functions create new tensors with the same shape but all values set to zero or one.
c = theano.tensor.zeros_like(a)
array([[0, 0],
[0, 0]])
Reorder the tensor dimensions
Sometimes we need to reorder the dimensions in a tensor. In the examples below, the dimensions in a two-dimensional matrix are first swapped. Then, ‘x’ is used to create a brand new dimension.
a.eval()
array([[1, 2],
[3, 4]])
c = a.dimshuffle((1,0))
array([[1, 3],
[2, 4]])
c = a.dimshuffle(('x',0,1))
array([[[1, 2],
[3, 4]]])
Indexing
Using Python indexing tricks can make life so much easier. In the example below, we make a separate list b containing line numbers, and use it to construct a new matrix which contains exactly the lines we want from the original matrix. This can be useful when dealing with word embeddings – we can put word ids into a list and use this to retrieve exactly the correct sequence of embeddings from the whole embedding matrix.
a = theano.shared(numpy.asarray([[1.0,2.0],[3.0,4.0]]), 'a')
array([[1., 2.],
[3., 4.]])
b = [1,1,0]
c = a[b]
array([[ 3., 4.],
[ 3., 4.],
[ 1., 2.]])
For assignment, we can’t do this:
a[0] = [0.0, 0.0]
But instead, we can use set_subtensor(), which takes as arguments the selection of the original matrix that we want to reassign, and the value we want to assign it to. It returns a new tensor that has the corresponding values modified.
c = theano.tensor.set_subtensor(a[0],[0.0, 0.0])
array([[ 0., 0.],
[ 3., 4.]])
11. Classifier Code Example
At this point, it’s time to move on to some more realistic examples.
Take a look at the code for a very basic classifier, which tries to train a small network on a tiny (but real) dataset. I won’t walk you through it line-by-line any more; you’ve learned all the necessary parts by now and there are comments in the code as well.
The task is to predict whether the GDP per capita for a country is more than the average GDP, based on the following features:
- Population density (per suqare km)
- Population growth rate (%)
- Urban population (%)
- Life expectancy at birth (years)
- Fertility rate (births per woman)
- Infant mortality (deaths per 1000 births)
- Enrolment in tertiary education (%)
- Unemployment (%)
- Estimated control of corruption (score)
- Estimated government effectiveness (score)
- Internet users (per 100 people)
The data/ directory contains the files for training (121 countries) and testing (40 countries). Each row represents one country, the first column is the label, followed by the features. The feature values have been normalised, by subtracting the mean and dividing by the standard deviation. The label is 1 if the GDP is more than average, and 0 otherwise.
Once you clone the github repository (or just download the data files), you can run the script with:
python classifier.py data/countries-classify-gdp-normalised.train.txt data/countries-classify-gdp-normalised.test.txt
The script will print information about 10 training epochs and the result on the test set:
Epoch: 0, Training_cost: 28.4304042768, Training_accuracy: 0.578512396694 Epoch: 1, Training_cost: 24.5186290354, Training_accuracy: 0.619834710744 Epoch: 2, Training_cost: 22.1283727037, Training_accuracy: 0.619834710744 Epoch: 3, Training_cost: 20.7941253329, Training_accuracy: 0.619834710744 Epoch: 4, Training_cost: 19.9641569475, Training_accuracy: 0.619834710744 Epoch: 5, Training_cost: 19.3749411377, Training_accuracy: 0.619834710744 Epoch: 6, Training_cost: 18.8899216914, Training_accuracy: 0.619834710744 Epoch: 7, Training_cost: 18.4006371608, Training_accuracy: 0.677685950413 Epoch: 8, Training_cost: 17.7210185975, Training_accuracy: 0.793388429752 Epoch: 9, Training_cost: 16.315597037, Training_accuracy: 0.876033057851 Test_cost: 5.01800578051, Test_accuracy: 0.925
12. Recurrent functions with scan
One more important operation to cover is scan, which can be used to create various recurrent functions: RNN, GRU, LSTM, etc.
Here is sample code for using scan to define a simple RNN over word vectors in the input_vectors matrix:
def rnn_step(x, previous_hidden_vector, W_input, W_recurrent):
hidden_vector = theano.tensor.dot(x, W_input) +
theano.tensor.dot(previous_hidden_vector, W_recurrent)
hidden_vector = theano.tensor.nnet.sigmoid(hidden_vector)
W_input = self.create_parameter_matrix('W_input', (word_embedding_size, recurrent_size))
W_recurrent = self.create_parameter_matrix('W_recurrent', (recurrent_size, recurrent_size))
initial_hidden_vector = theano.tensor.alloc(numpy.array(0, dtype=floatX), recurrent_size)
hidden_vector, _ = theano.scan(
rnn_step,
sequences = input_vectors,
outputs_info = initial_hidden_vector,
non_sequences = [W_input, W_recurrent]
)
hidden_vector = hidden_vector[-1]
The scan function is called on line 10 and it takes 4 important arguments:
- fn: The function that is called at every step of the iteration.
- sequences: The variables that we want to iterate over. If this is a matrix, we will be iterating over each row of that matrix.
- outputs_info: The values that we use as the previous recurrent values for the very first step. Usually these are just set to 0.
- non_sequences: Any additional variables that we want to pass into the function (fn) but don’t want to iterate over.
We’ve defined the helper function rnn_step on line 1, which gets called on each row of our input matrix. The scan function will be calling this rnn_step function internally, so we need to accept any arguments in the same order as Theano passes them. This is just something you need to know when dealing with scan. The order is as follows:
- First, the current items from the variables that we are iterating over. If we are iterating over a matrix, the current row is passed to the function.
- Next, anything that was output from the function at the previous time step. This is what we use to build recursive and recurrent representations. At the very first time step, the values will be those from outputs_info instead.
- Finally, anything we specified in non_sequences.
What comes out from the scan function contains the hidden states (eg the rnn_step outputs) at each step. Not just the last step, but all of them. So if you only want the last step, you need to explicitly retrieve it by indexing from -1 (the last element). Theano is actually smart enough to figure out that you’re only using the last result, and will optimise to discard all the intermediate ones.
In order to construct the weight matrices, I’m using a helper function (self.create_parameter_matrix, definition not shown here) which takes as input the variable name and the shape. This means I don’t need to define the weight initialisation part again each time.
13. RNN Classifier Code Example
Time to look at some more code, this time using recurrent functions and scan. The script is available at the Github repository. In this example, I’m using Gated Recurrent Units (GRU) from “Learning Phrase Representations using RNN Encoder-Decoder for Statistical Machine Translation” (Cho et al, 2014), which are essentially a simpler versions of LSTMs.
The task is to classify sentences into 5 classes, based on their fine-grained sentiment (very negative, slightly negative, neutral, slightly positive, very positive). We use the dataset published in “Recursive Deep Models for Semantic Compositionality Over a Sentiment Treebank” (Socher et al., 2013).
Start by downloading the dataset from http://nlp.stanford.edu/sentiment/ (the main zip file) and unpack it somewhere. Then, create training and test splits in the format that is more suitable for us, using the provided script in the repository:
python stanford_sentiment_extractor.py 1 full /path/to/sentiment/dataset/ > data/sentiment.train.txt python stanford_sentiment_extractor.py 2 full /path/to/sentiment/dataset/ > data/sentiment.test.txt
Now we can run the classifier with:
python rnnclassifier.py data/sentiment.train.txt data/sentiment.test.txt
The script will train for 3 passes over the training data, and will then print performance on the test data.
Epoch: 0 Cost: 25937.7372292 Accuracy: 0.285814606742 Epoch: 1 Cost: 21656.820174 Accuracy: 0.350655430712 Epoch: 2 Cost: 18020.619533 Accuracy: 0.429073033708 Test_cost: 4784.25137484 Test_accuracy: 0.388235294118
The accuracy on the test set is about 38%, which isn’t a great result. But it is quite a difficult task – the current state-of-the-art system (Tai ei al., 2015) achieves 50.9% accuracy, using a large amount of additional phrase-level annotations, and a much bigger network based on LSTMs and parse trees. As there are 5 classes to choose from, a random system would get 20% accuracy.
14. Running on a GPU
Theano is smart enough to move some parts of the processing to the GPU, as long as CUDA is installed and a graphics card is made available. To install CUDA, follow instructions on one of these links:
https://developer.nvidia.com/cuda-downloads
http://www.r-tutor.com/gpu-computing/cuda-installation/cuda7.5-ubuntu
Then, when running your Python script, you need to point Theano to the CUDA installation. I do this by setting the environment variables in the command line:
LD_LIBRARY_PATH=/usr/lib:/usr/local/cuda-7.5/lib64 THEANO_FLAGS='cuda.root=/usr/local/cuda-7.5,device=gpu,floatX=float32' python mycode.py
This command is for CUDA-7.5 in my system. You’ll need to make sure that the paths match the CUDA installation paths in your machine. If it works and Theano is using a GPU, the first line that gets printed will explicitly say so. Something like this:
Using gpu device 0: GeForce GTX 780
If you don’t get something similar, it probably means Theano is not properly hooked up to use the GPU.
At the time of writing, Theano only supports 32-bit variables on the GPU, and this is where the floatX=float32 setting comes it. It just allows you to set the data type during the execution of the script, without writing it into your code. For example, you can define your vectors like this:
x = theano.tensor.vector('x', dtype=config.floatX)
And now you can set floatX to be float32 when running the script on a GPU and float64 when running on your CPU.
Finally, if your machine has multiple GPUs, you can control which one is used for the script by setting device=gpu0, device=gpu1, etc. Based on personal experience, running multiple Theano jobs on the same GPU does not give any advantage, so it’s best to send them to different ones when possible.
15. Drawing the computation graph
Theano provides a command for printing a variable or a function, along with all the required computation, as an image:
f = theano.function([x], y) theano.printing.pydotprint(f, outfile="f.png", var_with_name_simple=True)
When dealing with very simple models, this can give a nice graphical representation. For example, here is a model from our minimal working example:
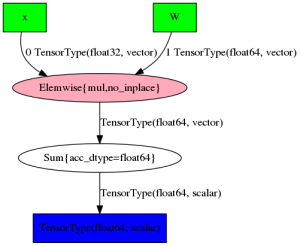
However, when the models get more and more complicated, the images also tend to get less informative:
16. Profiling
Finally, Theano also provides a useful tool for analysing bottlenecks in your code. Just set profile=True in THEANO_FLAGS, and it will print information about how much time is spent on different operations in your code.
THEANO_FLAGS='profile=True' python minimal_working_example.py

17. References
This concludes the Theano tutorial. If you haven’t yet had enough, take a look at the following links that I used for inspiration:
Official Theano homepage and documentation
Official Theano tutorial
A Simple Tutorial on Theano by Jiang Guo
Code samples for learning Theano by Alec Radford
wonderful tutorial, Thank you very much, o(^▽^)o
Thank you for your great tutorial.
I suspect that ‘h_prev’ and ‘_h’ are swapped at the line 41 of rnnclassifier.py , compared with eq. (7) on the paper of ‘Cho et al, 2014’.
h = (1.0 – z) * h_prev + z * _h
Is either one ok to use?
Hi Masataka,
Good point. Both of them will give a similar result, as the sigmoid function can equally well model z and (1-z). But for clarity I changed the code to be more similar to the original paper. Thanks.
Nice tutorial.
What is predicted_value?what is its importance?
In
# creating the network
n_features = len(data_train[0][1])
classifier = Classifier(n_features)
what n_features indicates?
Thank you
n_features is the size of the feature vector that is given as input to the network.
The network predicts a class for the data instance. If there are only 2 possible classes, we can do this by predicting a value between 0 and 1. If the predicted value is close to 0, we say it belongs to one class, and if it is close to 1, it belongs to the other class.
thank you for reply.
What will be the condition in training and testing loop if the number of classes are more than two?? How to predict the value for more than two classes??
Thank you!!
hi
How feature extraction is done in theano and neural network?
What do you mean by feature extraction?
feature extraction is separated technique to extract features you think they represent the data without redundancy.
Himmel, jetzt oute ich schon Exlesben Nach allem, was ich bisher von Dir gelesen habe, incl. der tweets, hatte ich da überhaupt keine Zweifel. Der Gaydar scheint bei Lesben doch nicht so richtig zu funktionieren. Ich werde Dich dann in den verschieben, da gibt es auch nette Frauen &n;;ps bNele Tabler
Small typo in
8. Functions
Theano functions are basically hooks for interacting with the “symbolic” graph.
Thanks!
You bought a used car and things do wear out. Why didn’t you check the car out when you bought it? Its your job to make sure you aren’t getting screwed.I don’t know about over there but in the US used cars are sold with a “limited wa8r1nty&#r22a; or “as is”. At best they will cover a few major things for a few months and at worst they cover nothing.
Yes sir. That too. Discipline is the bridge between thought and acmncplishmeot. He is young, and needs to mature this year. He got a taste of the nectar in the Holy Grail, hopefully he and his teamates burn with an intensity unknown to mankind to possess it in 2013.
I have two questions
1- why did you add the regularization term to by summing and adding all weights to the cost function, I test the code without it and it gave better result ?
2- is it true how I see it that we are updating the weights on each vector iteration and not on each epoch. which I means we are updating on single vector and not on batch?
1. It’s a standard L2 regularisation. I just added it to show the implementation, but didn’t try to choose an optimal value for l2_regularisation.
2. Yes. I haven’t implemented batch training here. This network is trained one instance at a time.
though we ha87;#d21n&t seen them on the mainland, we figured they would be everywhere on Skye. Yet, after arriving on the island, we spent the day driving around Broadford and Portree and the
Hi,
Thank you for sharing this.
Is the initiation of initial_hidden_vector applied every time we call the ‘train’ function from the main function? i.e. the h_prev will always be initiated with 0.0 when we call the function.
Thanks..
Yes, the initial_hidden_vector has a static value of zeros.
thank you for reply.
What will be the condition in training and testing loop if the number of classes are more than two?? How to predict the value for more than two classes??
Thank you!!
There’s a variable n_classes that controls how many different classes the output layer has.
hi
I have tried to implement the classifier.py code on cpu and gpu. I have created .theanorc file to configure theano and gpu. I tried for different number of epochs but cpu speed is always greater than gpu. My .theanorc file is:
[global]
floatX = float32
device = gpu0
mode=FAST_RUN
[gcc]
cxxflaags = -ID:\MinGW\include
[nvcc]
fastmath = True
[lib]
cnmem = 1
I am using Tesla c2075 gpu. I want to increase the execution speed on gpu. How to achieve this?
If you run your code and it prints the name of your GPU into the error output, then that generally means Theano is using the GPU. If it’s running on the GPU and you still need to make it faster, then you probably need to think of ways of optimising the model itself.
Pingback:Deep learning SW libraries | Bits and pieces
Thanks for the post,
I tried to modify the GRU code to LSTM. However it gives much poorer result (it stabilised to 0.25 even with many iterations). Below is the code “lstm_step”:
def lstm_step(x, h_prev, c_prev, W_xm, W_hm, W_xh, W_hh):
m = theano.tensor.nnet.sigmoid(theano.tensor.dot(x, W_xm) + theano.tensor.dot(h_prev, W_hm))
i = _slice(m, 0, 3)
f = _slice(m, 1, 3)
o = _slice(m, 2, 3)
g = theano.tensor.tanh(theano.tensor.dot(x, W_xh) + theano.tensor.dot(h_prev, W_hh))
c = c_prev * f + g * i
h = theano.tensor.tanh(c) * o
return [h, c]
In the scan block I passed
outputs_info = [initial_hidden_vector, initial_internal_vector],
Did I make a mistake or just the lstm overfits the data? Thanks in advance!
Hi Yiping,
There seems to be quite a few variations of LSTM going around are yours is one of them. If you want to use the “real” LSTM, I’d recomment following the formulas here:
http://www.cs.toronto.edu/~graves/asru_2013.pdf
Notice there’s a bias term, some of the weights are diagonal, and the output gate is calculated differently from the input and forget gates.
But to be fair, your version would probably work quite similarly.
The low performance could be because of overfitting indeed. You could monitor the performance on training and development sets – if the training accuracy goes unreasonably high and development accuracy starts to drop, you’ve got overfitting and need to regularise somehow.
Very nice. I’m looking forward to your tutorial on tensorflow
(https://www.tensorflow.org/ has a good picture of a dataflow graph, the main idea.)
Should anyone want to print gradients in the loop:
theano-example-how-to-monitor-gradients.py under https://gist.github.com/denis-bz .
Unfortunately Firefox mangles your tutorial, prints one page then comments (on mac osx 10.8);
if you could put up a pdf too, even more people would read it.
Thanks!
That’s odd, I just checked the page with Firefox 49.0.2 on Ubuntu and it looked fine. What version are you using?
It’s the mac html-to-pdf, so don’t bother, thanks.
In Firefox 48.0.2 (the max for macosx 10.8, grr) ALL the text from the “deep learning” picture up to comments is squeezed into a narrow box to the right of the picture.
Just tried Safari, which squeezes a bit, then recovers.
I’ve been loonkig for a post like this for an age
We’ve arrived at the end of the line and I have what I need!
Thanks a lot!
I am a new guy in theano,When i run this code on Spyder,there is an error…
“IndexError: list index out of range” and its hard for me to find what’s wrong with it……
Looking forward to your reply
Hi Mark,
1. Which code specifically?
2. What is the full error?
Hi,Thanks for your reply, i copied all my running information as follows:
runfile(‘F:/theano learning/theano-tutorial-master/classifier.py’, wdir=’F:/theano learning/theano-tutorial-master’)
Using gpu device 0: GeForce GTX 950 (CNMeM is disabled, cuDNN not available)
Traceback (most recent call last):
File “”, line 1, in
runfile(‘F:/theano learning/theano-tutorial-master/classifier.py’, wdir=’F:/theano learning/theano-tutorial-master’)
File “e:\Users\win10\Anaconda2\lib\site-packages\spyder\utils\site\sitecustomize.py”, line 866, in runfile
execfile(filename, namespace)
File “e:\Users\win10\Anaconda2\lib\site-packages\spyder\utils\site\sitecustomize.py”, line 87, in execfile
exec(compile(scripttext, filename, ‘exec’), glob, loc)
File “F:/theano learning/theano-tutorial-master/classifier.py”, line 65, in
path_train = sys.argv[1]
IndexError: list index out of range
may these be useful to you
You need to pass the data files as argument. Take a look at the readme file in the repository for instructions on executing the script.
Hi Marek, thank you so much for your extremely helpful tutorial on Theano.
Would you mind explaining what the
[0]means in the RnnClassifier?output = theano.tensor.nnet.softmax([theano.tensor.dot(W_output, hidden_vector)])[0]
Thanks!
Pingback:Getting Started with the Conditional Image Generation Project – Site Title
Thanks for sharing the tutorial.
Thanks, this was one of the clearest primers on using theano for RNNs that I found. The only thing I couldn’t get to work is the computation graph. Even after I installed graphiz, my pydot kept saying it couldn’t find graphiz.
Ken
Just going through the tutorial and found an interesting issue while compiling Point 9 Minimal Training Example.
The error posed is: TypeError: (‘Bad input argument to theano function with name “D:/Theano practice/grads.py:15” at index 0 (0-based). \nBacktrace when that variable is created:\n\n
x = theano.tensor.fvector(\’x\’)\n’, ‘TensorType(float32, vector) cannot store accurately value [0.1, 1], it would be represented as [ 0.1 1. ]. If you do not mind this precision loss, you can: 1) explicitly convert your data to a numpy array of dtype float32, or 2) set “allow_input_downcast=True” when calling “function”.’, [0.1, 1])
Strangely the code works some time but not always.
The solution I could found was to use use “In” class attributes to allow my function to downcast. My solution is :
f = theano.function([In(x,strict=False,allow_downcast=True), target], y, updates=updates)
carry on nice article
Τhеre is certainly a great deal to learn aboսt this subject.
I love all of thе points you made.
Hi Marek,
This tutorial is great! I started studying neural networks a couple of weeks ago and I have some questions to you about your code.
1) In section 9 and 11 you have this row theano.tensor.sqr(predicted_value – target_value).sum() . Difference between section 9 and 11 is that you have there this term “sum()”. Can’t understand why do u have it there? I know that we have to compute sum of residuals^{2} but if so, why don’t you have this term in the section 9 as well?
2) Next question is about training. As far as I know, we have to compute argmin of the cost function with respect to weights. Thus, we have to take all the training data and the target values and minimize the sum of residuals^{2}. However, I can’t understand how training in your codes is provided.
I think that my questions can explained with the fact that I understand syntax of the code in a wrong way but I would be really pleased if you answer me.
Thank you.
P.S. I saw that you are doing NLP. This is my research project. Is it possible to write you an email and talk about it a little bit?
Hi Marko,
1) In section 9, we have a toy example where we’re updating the parameters for each datapoint, so the sum is not necessary. The code in section 11 is written so that we could be working with batches, therefore summing over all the datapoints in the batch becomes necessary.
2) We don’t actually compute argmin, but use gradient descent. We define a differentiable cost function, then calculate gradients for each parameter and update all the values so that they slightly move towards predicting the correct answer each time. If you google, I’m sure you’ll find more in-depth explanations of gradient descent.
Sure, feel free to drop me an email.
Marek
best site how to write a analysis
hello there everyone , I am very naive with theano and need a bit help …
I have to use Theano to get the w_0 and w_1 parameters of the following model:
y = math.log(1 + w_0 * |x|) + (w_1 * |x|)
I have created a dataset (basically single arrays of 101 rows) and now i cant find a way to calculate these w0 and w1 values with theano … can anyone please guide me a bit ?
it will be really helpful …
YOURURL.com hydraruzxpnew4af
Pingback:How to Calculate Matrices in Python Without NumPy - Web Hosting
Pingback:Theano – OpenWing – Open Platform for AIoT Devices