Staying on top of recent work is an important part of being a good researcher, but this can be quite difficult. Thousands of new papers are published every year at the main ML and NLP conferences, not to mention all the specialised workshops and everything that shows up on ArXiv. Going through all of them, even just to find the papers that you want to read in more depth, can be very time-consuming.
In this post, I have summarised 50 papers. After going through a paper, if I had the chance, I would write down a few notes and summarise the work in a couple of sentences. These are not meant as reviews – I’m not commenting on whether I think the paper is good or not. But I do try to present the crux of the paper as bluntly as possible, without unnecessary sales tactics. Hopefully this can give you the general idea of 50 papers, in roughly 20 minutes of reading time.
The papers are not selected or ordered based on any criteria. It is not a list of the best papers I have read, more like a random sample. The only filter that I applied was to exclude papers older than 2016, as the goal is to give an overview of the more recent work.
I set out to summarise 50 papers. Once I was done, I thought this would be a sensible place to summarise my own work as well. So at the end of the list you will also find brief summaries of the papers I published in 2017.
Let’s get started.
1. A Thorough Examination of the CNN/Daily Mail Reading Comprehension Task
Danqi Chen, Jason Bolton, Christopher D. Manning. Stanford. ACL 2016.
https://arxiv.org/pdf/1606.02858.pdf
Hermann et al (2015) created a dataset for testing reading comprehension by extracting summarised bullet points from CNN and Daily Mail. All the entities in the text are anonymised and the task is to place correct entities into empty slots based on the news article.
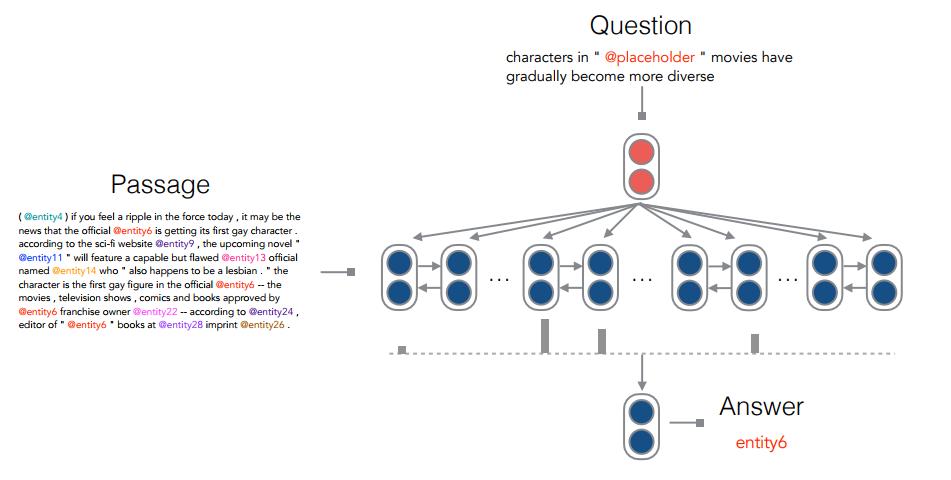
This paper has hand-reviewed 100 samples from the dataset and concludes that around 25% of the questions are difficult or impossible to answer even for a human, mostly due to the anonymisation process. They present a simple classifier that achieves unexpectedly good results, and a neural network based on attention that beats all previous results by quite a margin.
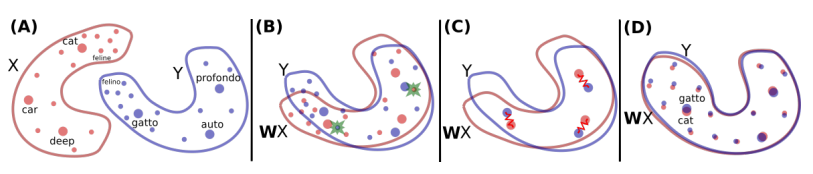
2. Word Translation Without Parallel Data
Alexis Conneau, Guillaume Lample, Marc’Aurelio Ranzato, Ludovic Denoyer, Hervé Jégou. Facebook, Le Mans, Sorbonne. ArXiv 2017.
https://arxiv.org/pdf/1710.04087.pdf
Inducing word translations using only monolingual corpora for two languages. Separate embeddings are trained for each language and a mapping is learned though an adversarial objective, along with an orthogonality constraint on the most frequent words. A strategy for an unsupervised stopping criterion is also proposed.