My previous post on summarising 57 research papers turned out to be quite useful for people working in this field, so it is about time for a sequel.
Below you will find short summaries of a number of different research papers published in the areas of Machine Learning and Natural Language Processing in the past couple of years (2017-2019). They cover a wide range of different topics, authors and venues. These are not meant to be reviews showing my subjective opinion, but instead I aim to provide a blunt and concise overview of the core contribution of each publication.
Given how many papers are published in our area every year, it is getting more and more difficult to keep track of all of them. The goal of this post is to save some time for both new and experienced readers in the field and allow them to get a quick overview of 74 research papers in about 30 minutes reading time.
I set out to post 60 summaries (up from 50 compared to last time). At the end, I also include the summaries for my own published papers since the last iteration (papers 61-74).
Here we go.
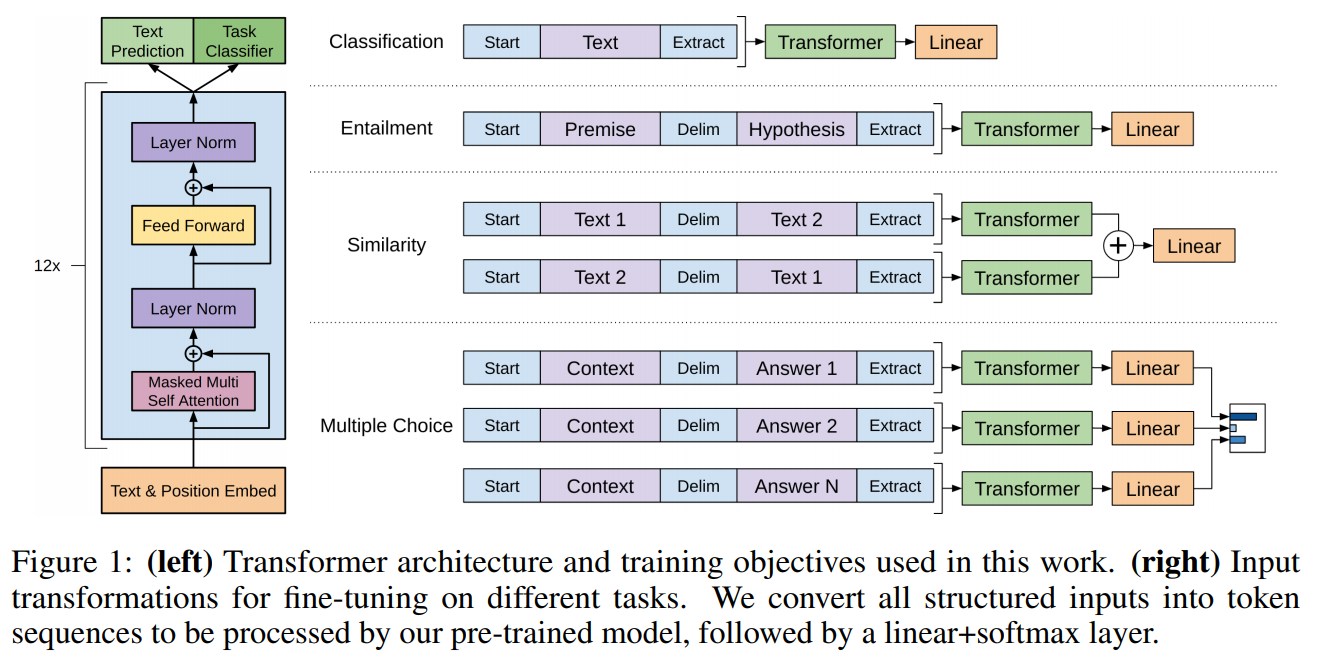
1. Improving Language Understanding by Generative Pre-Training
Alec Radford, Karthik Narasimhan, Tim Salimans, Ilya Sutskever. OpenAI. 2018.
https://s3-us-west-2.amazonaws.com/openai-assets/research-covers/language-unsupervised/language_understanding_paper.pdf
A transformer architecture that is trained as a language model on a large corpus, then fine-tuned for individual text classification and similarity tasks. Multiple sentences are combined together into a single sequence using delimiters in order to work with the same model. Reporting high results on entailment, question answering and semantic similarity tasks.
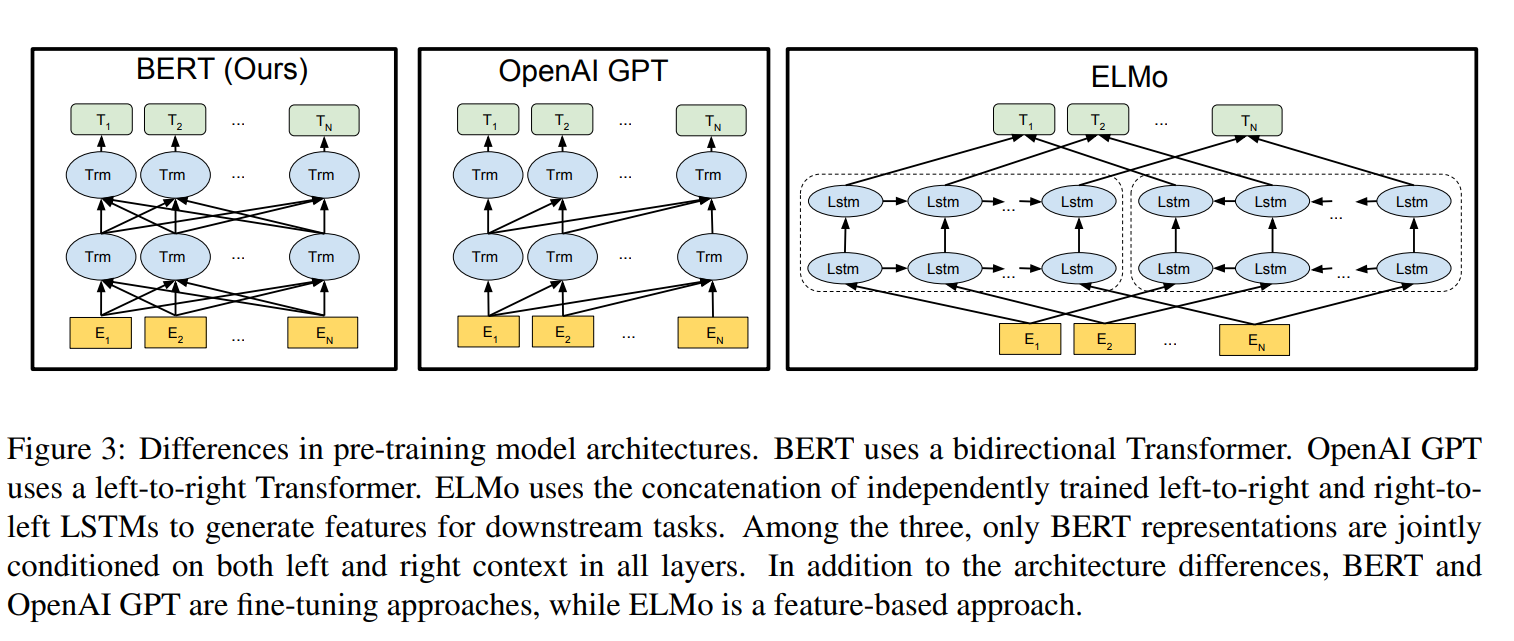
2. BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding
Jacob Devlin, Ming-Wei Chang, Kenton Lee, Kristina Toutanova. Google. NAACL 2019.
https://www.aclweb.org/anthology/N19-1423.pdf
A bidirectional transformer architecture for pre-training language representations. The model is optimized on unlabaled data by 1) predicting masked words in the input sequence, and 2) predicting whether the input sequences occur together. The parameters can then be fine-tuned for a specific task, such as classifying sentences, sentence pairs, or tokens.
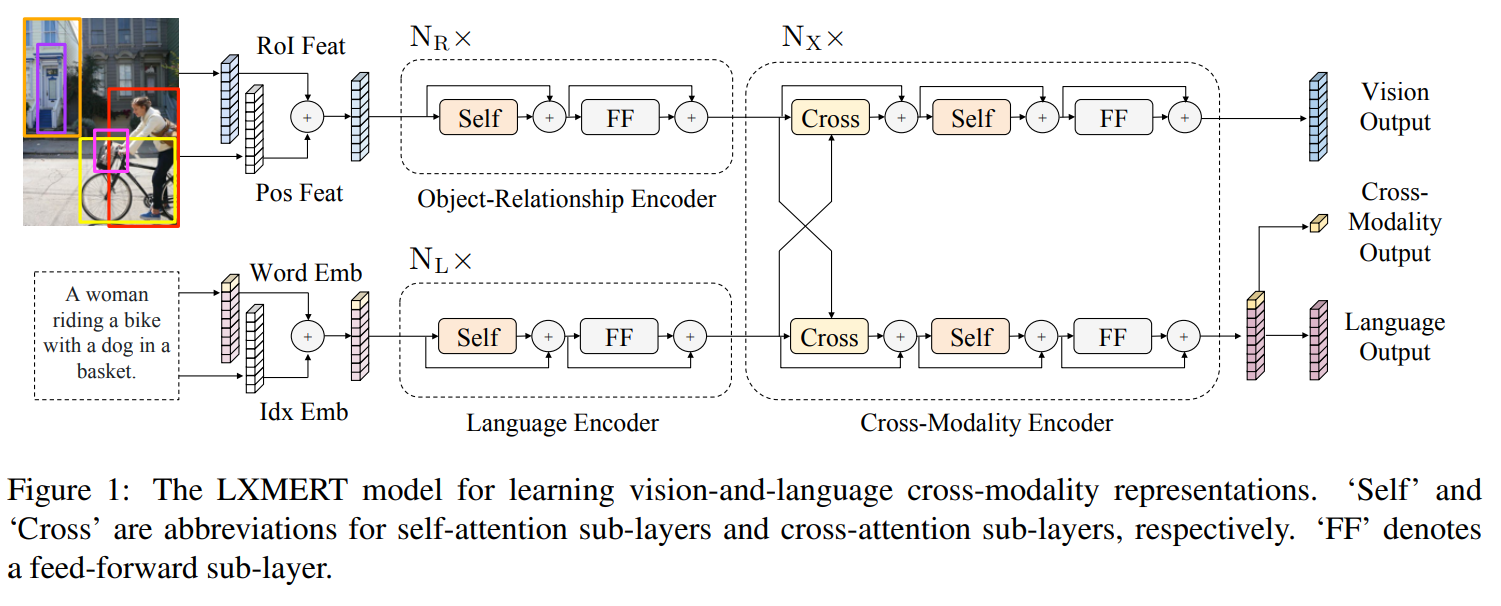
3. LXMERT: Learning Cross-Modality Encoder Representations from Transformers
Hao Tan, Mohit Bansal. UNC. ArXiv 2019.
https://arxiv.org/pdf/1908.07490.pdf
Building a cross-modal pre-trained model for both vision and language. Both images and text are encoded and attended over jointly with a cross-modal encoder, the model is then optimized with both unimodal and multimodal tasks (masked LM, image classification, image-caption matching, visual QA).
The model achieves new state-of-the-art on several VQA datasets.