My previous post on summarising 57 research papers turned out to be quite useful for people working in this field, so it is about time for a sequel.
Below you will find short summaries of a number of different research papers published in the areas of Machine Learning and Natural Language Processing in the past couple of years (2017-2019). They cover a wide range of different topics, authors and venues. These are not meant to be reviews showing my subjective opinion, but instead I aim to provide a blunt and concise overview of the core contribution of each publication.
Given how many papers are published in our area every year, it is getting more and more difficult to keep track of all of them. The goal of this post is to save some time for both new and experienced readers in the field and allow them to get a quick overview of 74 research papers in about 30 minutes reading time.
I set out to post 60 summaries (up from 50 compared to last time). At the end, I also include the summaries for my own published papers since the last iteration (papers 61-74).
Here we go.
1. Improving Language Understanding by Generative Pre-Training
Alec Radford, Karthik Narasimhan, Tim Salimans, Ilya Sutskever. OpenAI. 2018.
https://s3-us-west-2.amazonaws.com/openai-assets/research-covers/language-unsupervised/language_understanding_paper.pdf
A transformer architecture that is trained as a language model on a large corpus, then fine-tuned for individual text classification and similarity tasks. Multiple sentences are combined together into a single sequence using delimiters in order to work with the same model. Reporting high results on entailment, question answering and semantic similarity tasks.
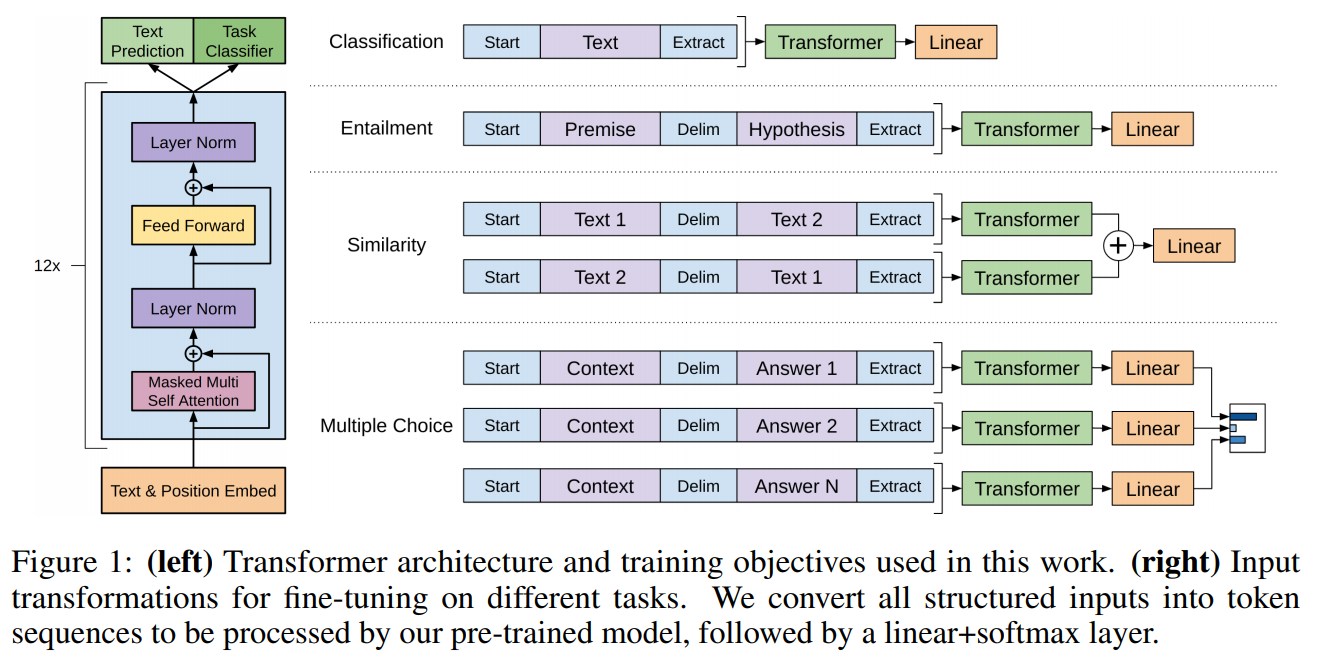
2. BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding
Jacob Devlin, Ming-Wei Chang, Kenton Lee, Kristina Toutanova. Google. NAACL 2019.
https://www.aclweb.org/anthology/N19-1423.pdf
A bidirectional transformer architecture for pre-training language representations. The model is optimized on unlabaled data by 1) predicting masked words in the input sequence, and 2) predicting whether the input sequences occur together. The parameters can then be fine-tuned for a specific task, such as classifying sentences, sentence pairs, or tokens.
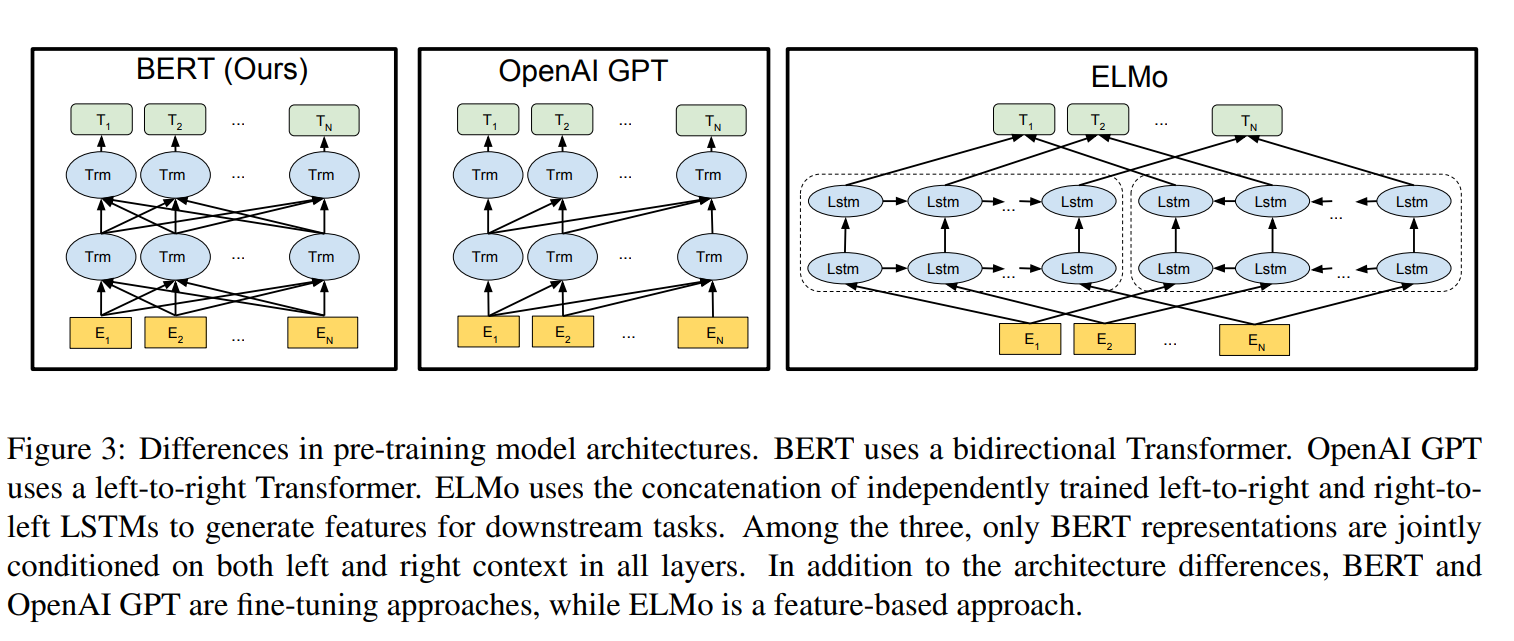
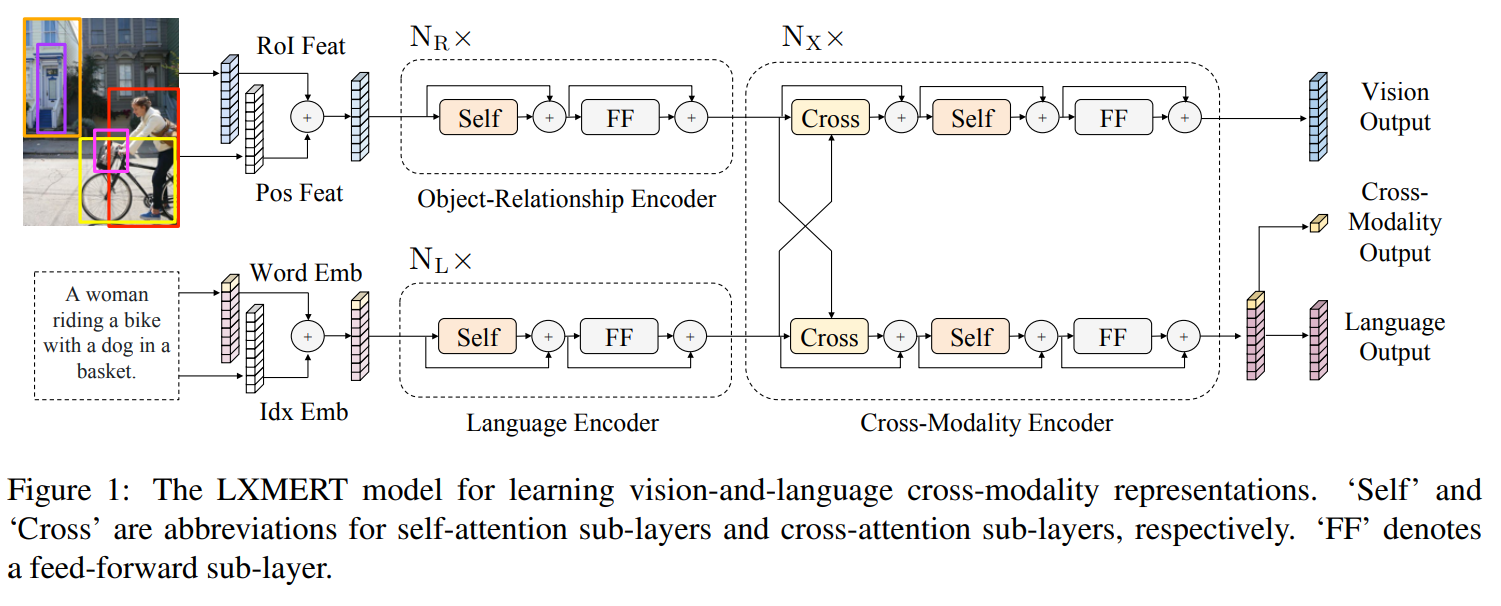
3. LXMERT: Learning Cross-Modality Encoder Representations from Transformers
Hao Tan, Mohit Bansal. UNC. ArXiv 2019.
https://arxiv.org/pdf/1908.07490.pdf
Building a cross-modal pre-trained model for both vision and language. Both images and text are encoded and attended over jointly with a cross-modal encoder, the model is then optimized with both unimodal and multimodal tasks (masked LM, image classification, image-caption matching, visual QA).
The model achieves new state-of-the-art on several VQA datasets.
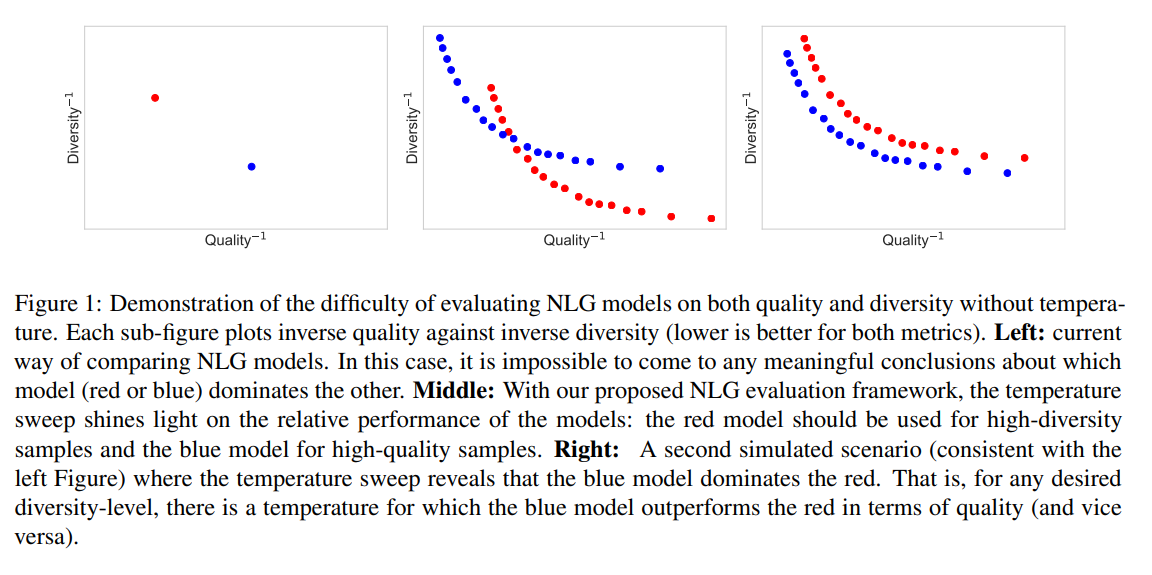
4. Language GANs Falling Short
Massimo Caccia, Lucas Caccia, William Fedus, Hugo Larochelle, Joelle Pineau, Laurent Charlin. Montréal, McGill, Facebook, Google. ArXiv 2018.
https://arxiv.org/pdf/1811.02549.pdf
Compares different text-based GANs on language generation and finds that MLE language models still outperform all of them. The tuning of a temperature parameter on the output distribution is proposed for controlling the balance between quality and diversity of the generation. The models are evaluated at different values of this parameter space, revealing the different operating areas of each architecture.
5. Unsupervised Recurrent Neural Network Grammars
Yoon Kim, Alexander Rush, Lei Yu, Adhiguna Kuncoro, Chris Dyer, Gábor Melis. Harvard, Oxford, DeepMind. NAACL 2019.
https://www.aclweb.org/anthology/N19-1114.pdf
Extending recurrent neural network grammars to the unsupervised setting, discovering constituency parses only from plain text. They train jointly 1) a generative network that sequentially generates both a binary tree structure and the words in the leaves, and 2) an inference network that generates a tree conditioned on the whole sentence. The generative part is then evaluated as a language model, while the inference network is evaluated as an unsupervised unlabeled constituency parser.
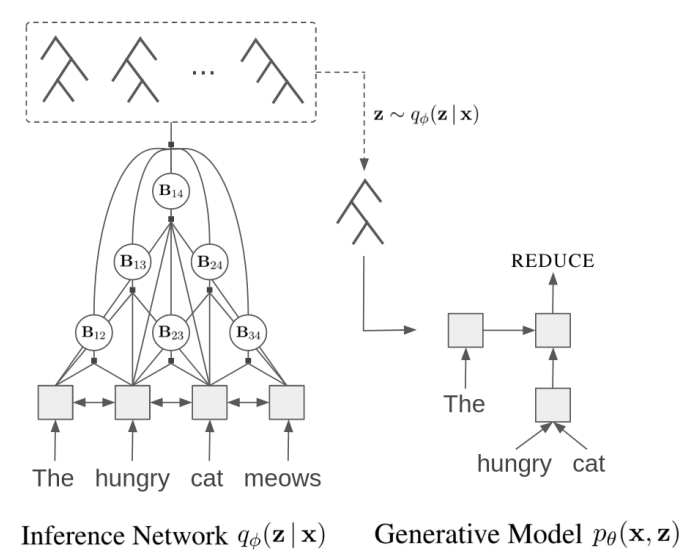
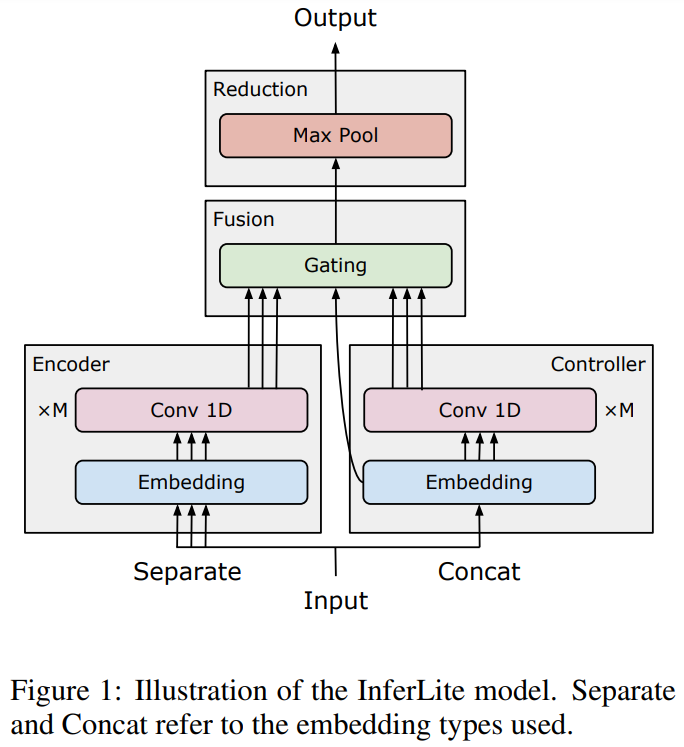
6. InferLite: Simple Universal Sentence Representations from Natural Language Inference Data
Jamie Kiros, William Chan. Toronto. EMNLP 2018.
https://www.aclweb.org/anthology/D18-1524.pdf
The paper describes a method for learning general-purpose sentence representations. Word embeddings from different sources are mapped to a new space and combined with attention. An optional convolution module is also used. A sentence representation is calculated using a max-pooling operation over word representations. The model is optimised using NLI data. Evaluation is performed on a number of sentence classification and similarity datasets.
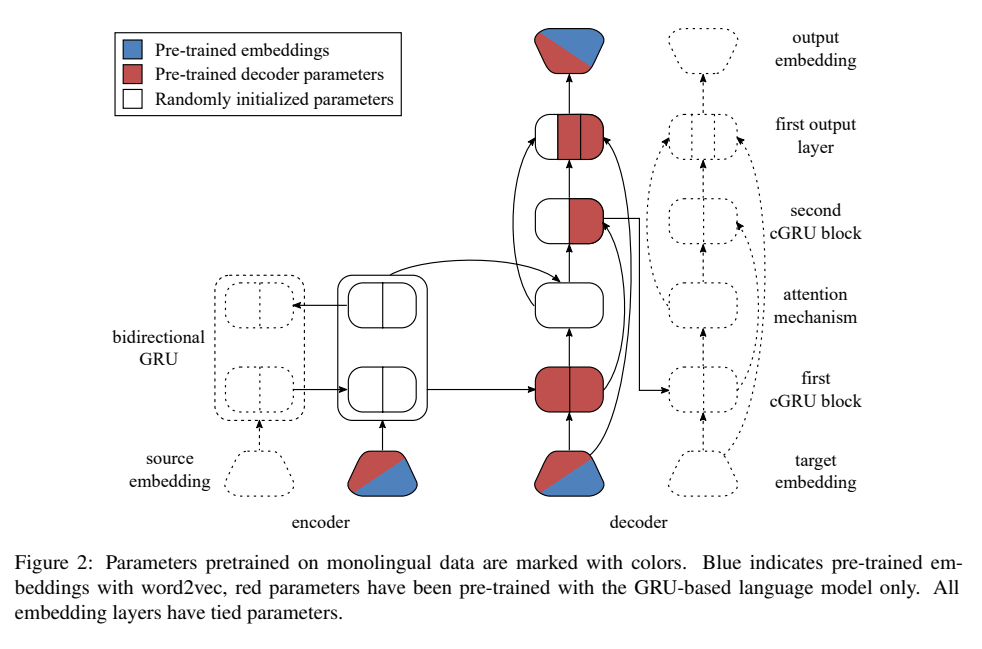
7. Approaching Neural Grammatical Error Correction as a Low-Resource Machine Translation Task
Marcin Junczys-Dowmunt, Roman Grundkiewicz, Shubha Guha, Kenneth Heafield. Microsoft, Edinburgh. NAACL 2018.
https://www.aclweb.org/anthology/N18-1055.pdf
The paper describes a series of data processing and model architecture choices that improve the results of a neural MT model for error correction.
These include separating words into sub-tokens, sampling strategies, a custom version of dropout, tied embeddings, weighting edits higher during optimisation, pre-training the model and the embeddings, and combination with a language model.
Evaluations on CoNLL 2014 and JFLEG show a considerable improvement over previous best results of neural models, making this work comparable to state-of-the art on error correction.
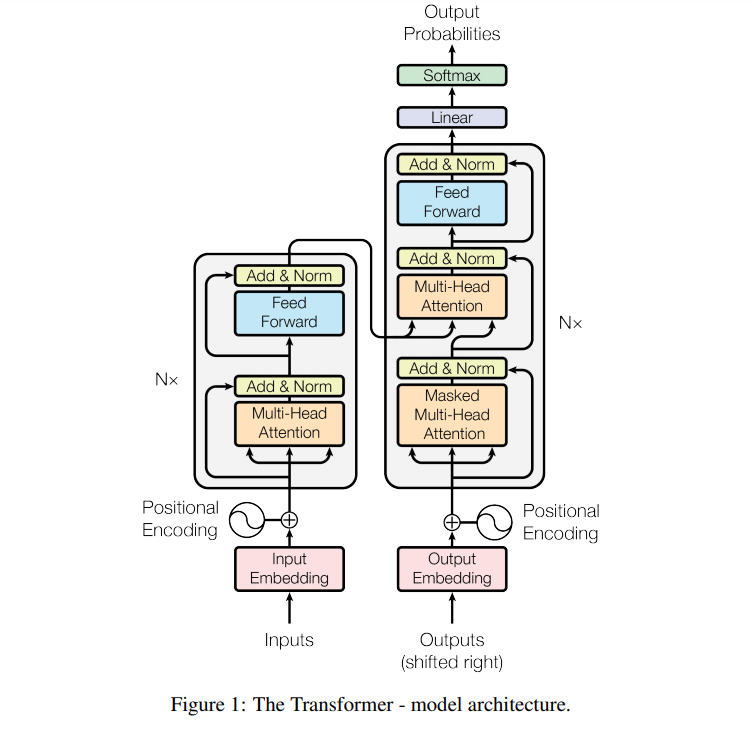
8. Attention Is All You Need
Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N. Gomez, Lukasz Kaiser, Illia Polosukhin. Google, Toronto. NIPS 2017.
https://papers.nips.cc/paper/7181-attention-is-all-you-need.pdf
Replacing RNNs in a seq2seq model with multi-layer attention mechanisms. Also using multi-head attention, where 8 different attention modules are used in parallel and the result is concatenated. They achieve good results on English-French and English-German translation.
9. Deep Contextualized Word Representations
Matthew Peters, Mark Neumann, Mohit Iyyer, Matt Gardner, Christopher Clark, Kenton Lee, Luke Zettlemoyer. Allen Institute, Washington. NAACL 2018.
https://www.aclweb.org/anthology/N18-1202.pdf
A bidirectional LSTM is trained as a language model and its hidden layers are used to augment word embeddings for other models. Representations from different layers of the fixed LM are combined together, then concatenated with a regular word embedding and fed into a downstream model. They show improvements on a range of tasks, including QA; NER and SNLI.
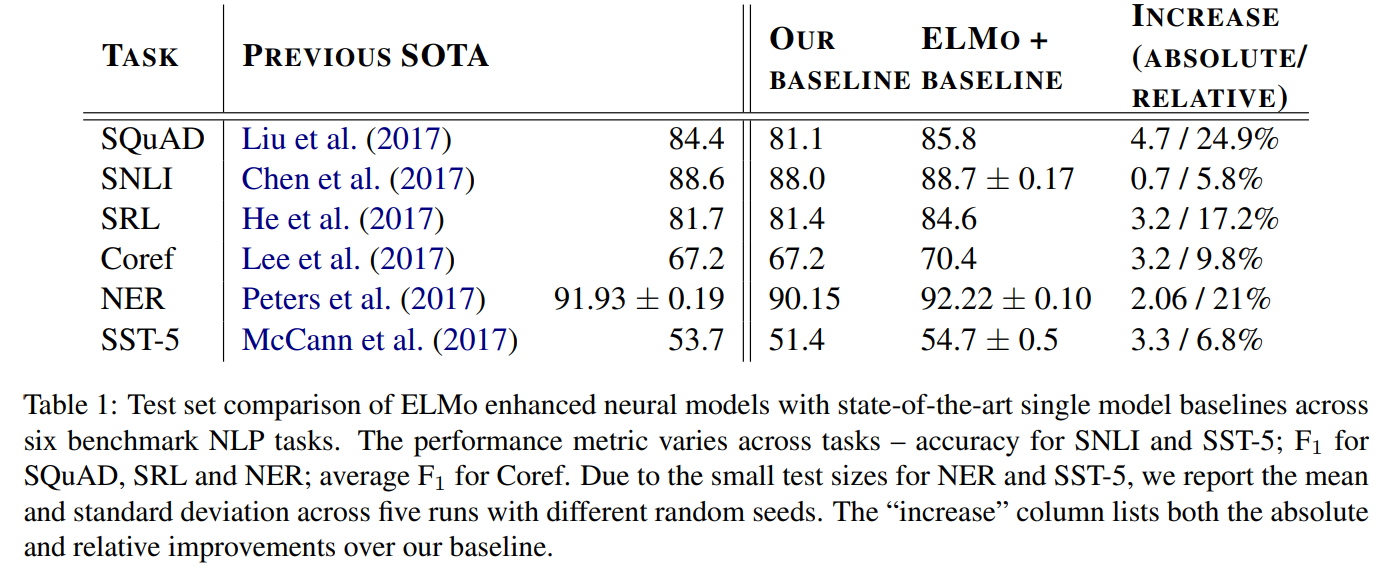
10. Long Short-Term Memory with Dynamic Skip Connections
Tao Gui, Qi Zhang, Lujun Zhao, Yaosong Lin, Minlong Peng, Jingjing Gong, Xuanjing Huang. Fudan. AAAI 2019.
https://aaai.org/ojs/index.php/AAAI/article/view/4613/4491
The paper describes an extension to LSTMs for sequence labeling, where the model is able to incorporate the state from one previous step directly into the current step.
This is achieved by a separate module that predicts one of K possible steps that will be chosen for inclusion. As the discrete steps are non-differentiable, the model is trained through reinforcement learning, optimising the token-level loss.
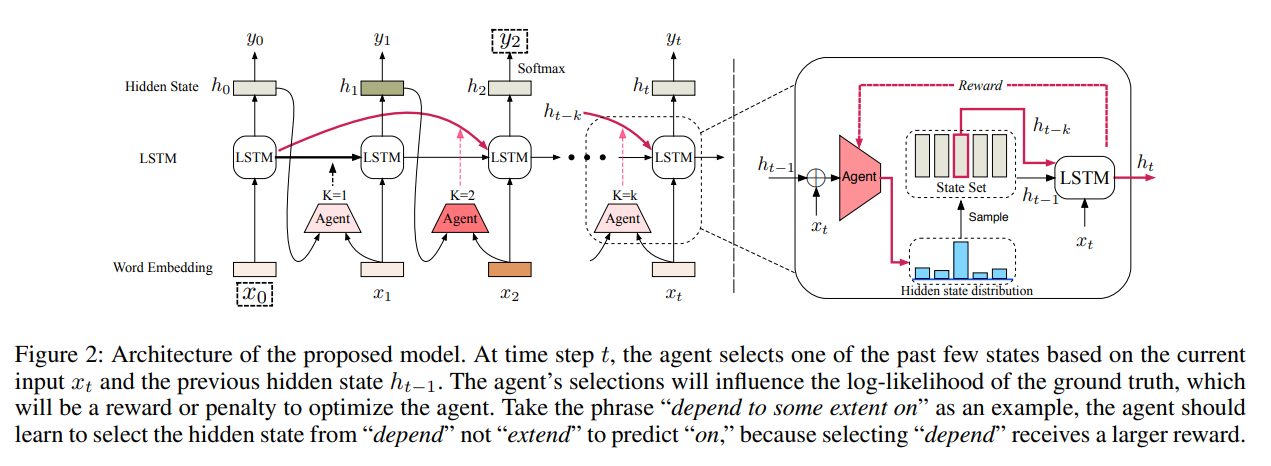
11. Learning Distributed Event Representations with a Multi-Task Approach
Xudong Hong, Asad Sayeed, Vera Demberg. Saarland, Gothenburg. *SEM 2018.
https://www.aclweb.org/anthology/S18-2002.pdf
The paper describes a neural model for predicting arguments and relation types, based on other arguments and relations describing the same event.
The input words and relations are encoded into a vector representation, then used to predict both the missing word (conditioned on the relation) and the missing relation type (conditioned on the word).
Several different configurations are explored, using different composition methods and making use of residual connections.
12. Combining Abstractness and Language-specific Theoretical Indicators for Detecting Non-Literal Usage of Estonian Particle Verbs
Eleri Aedmaa, Maximilian Köper, Sabine Schulte im Walde. Tartu, Stuttgart. NAACL 2018.
https://www.aclweb.org/anthology/N18-4002.pdf
The paper describes an approach for detecting non-literal usage of particle verbs in Estonian. The authors construct a new dataset of 1490 sentences and annotate it for metaphorical or literal meaning. They then construct a range of features and train a random forest classifier to detect these metaphorical uses. In the process, an automatically generated dataset of abstractness scores for 243,675 Estonian lemmas is created.
13. Generating Token-Level Explanations for Natural Language Inference
James Thorne, Andreas Vlachos, Christos Christodoulopoulos, Arpit Mittal. Cambridge, Amazon. NAACL 2019.
https://www.aclweb.org/anthology/N19-1101.pdf
Constructing a system for NLI that explains its decisions by pointing to the most relevant parts of the input. The architecture is based on self-attention, using the attention weights as token-level decisions. While the result is not as accurate as LIME, it is about 6000 times faster.
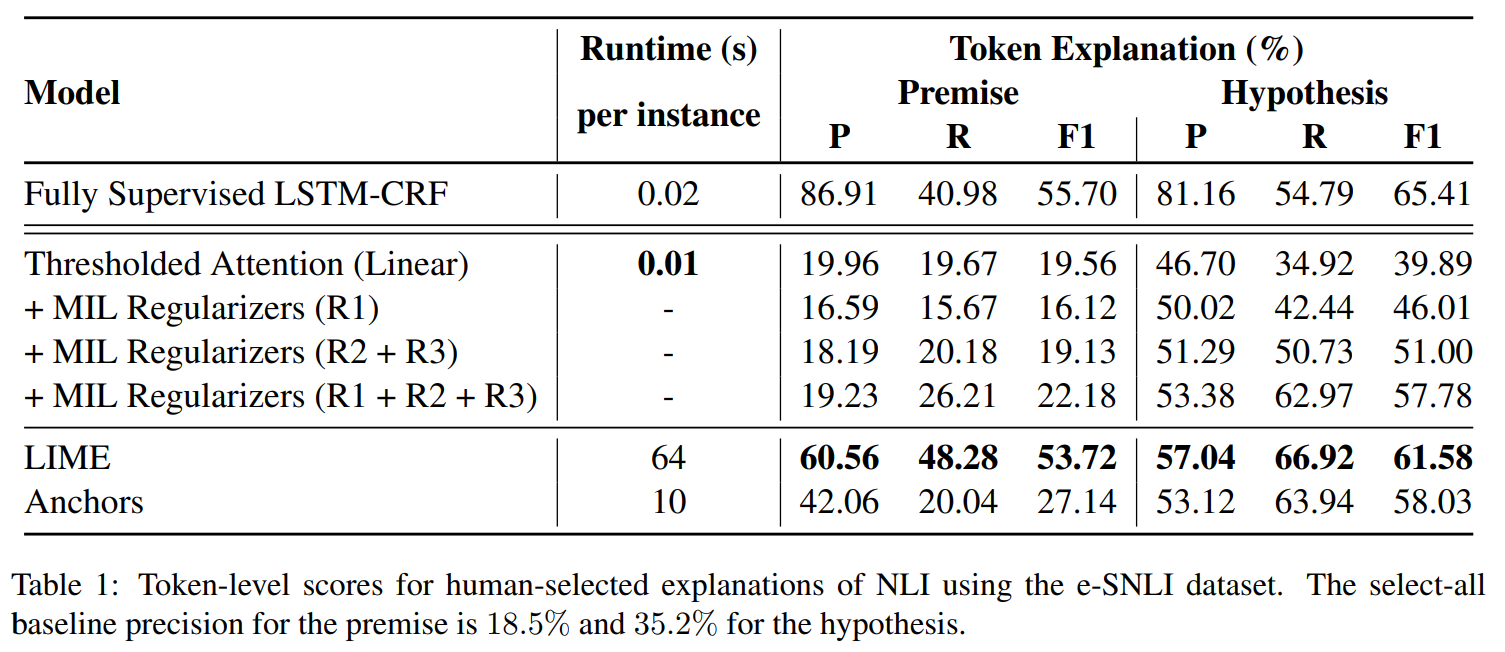
14. Efficient Contextualized Representation: Language Model Pruning for Sequence Labeling
Liyuan Liu, Xiang Ren, Jingbo Shang, Xiaotao Gu, Jian Peng, Jiawei Han. Illinois, SoCal. EMNLP 2018.
https://www.aclweb.org/anthology/D18-1153.pdf
The paper describes a method for training and pruning a language model, which can be integrated with a sequence labeler. The model is a multi-layer LSTM, with direct connections between all possible layers. The pruning process involves removing some LSTM layers from the model.
15. Meaningless yet meaningful: Morphology grounded subword-level NMT
Tamali Banerjee, Pushpak Bhattacharyya. Bombay. SCLEM 2018.
https://www.aclweb.org/anthology/W18-1207.pdf
The paper proposes using two subword creation systems in a pipeline, instead of either of them separately. Morphessor break words into linguistically-motivated morphs, whereas Byte Pair Encoding uses co-occurrence statistics to combine smaller units into larger subwords. The paper proposes processing the text first with Morphessor, then with BPE to get the benefit of both approaches. The subword creation process is evaluated on the task of translation.
16. Who is Killed by Police: Introducing Supervised Attention for Hierarchical LSTMs
Minh Nguyen, Thien Huu Nguyen. Hanoi, Montreal, Oregon. COLING 2018.
https://www.aclweb.org/anthology/C18-1193.pdf
The paper describes a model for classifying collections of sentences based on whether they refer to a person who has been killed by police. The system uses a two-level LSTM architecture for composing representations of sentences and full texts. The authors investigate two extensions for directly applying supervision to the attention weights.
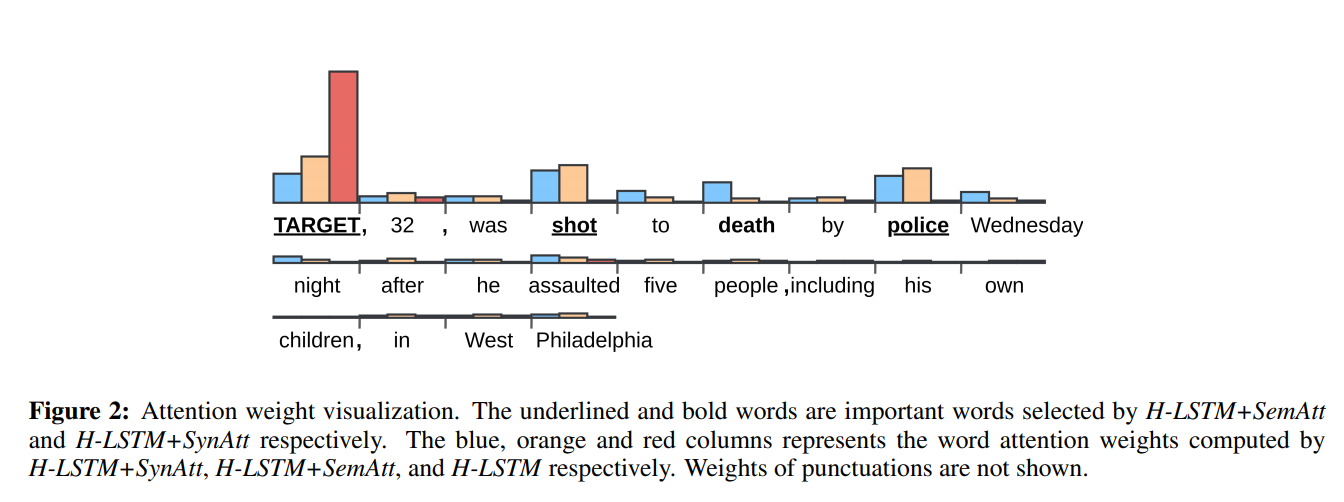
17. Corpus Specificity in LSA and Word2vec: The Role of Out-of-Domain Documents
Edgar Altszyler, Mariano Sigman, Diego Fernández Slezak. Conicet. RepL4NLP 2018.
https://www.aclweb.org/anthology/W18-3001.pdf
The paper investigates the impact of corpus size on the word embedding quality, when using LSA and word2vec. It concludes that word2vec consistently benefits from more data, whereas LDA benefits from data that is more topic-relevant.
18. Semi-Supervised Learning with Auxiliary Evaluation Component for Large Scale e-Commerce Text Classification
Mingkuan Liu, Musen Wen, Selcuk Kopru, Xianjing Liu, Alan Lu. eBay. DeepLo 2018.
https://www.aclweb.org/anthology/W18-3409.pdf
The paper describes a semi-supervised setup for text classification, assuming a small amount of annotated data and a large amount of unlabeled data. Two models are trained in tandem: a regular text classifier and a model that predicts whether the first model has made a mistake. The classifier is then used to predict labels for the unannotated examples and the second model is used to select examples that get included into the training data.
19. Multi-Task Active Learning for Neural Semantic Role Labeling on Low Resource Conversational Corpus
Fariz Ikhwantri, Samuel Louvan, Kemal Kurniawan, Bagas Abisena, Valdi Rachman, Alfan Farizki Wicaksono, Rahmad Mahendra. Jakarta, Trento, Depok. DeepLo 2018.
https://www.aclweb.org/anthology/W18-3406.pdf
The paper describes a sequence tagging model for semantic role labeling. The model uses multi-task learning, through the task of entity recognition, also combined with active learning. It is evaluated on a new SRL dataset in Indonesian which will be made available.
20. Learning with Latent Language
Jacob Andreas, Dan Klein, Sergey Levine. Berkeley. NAACL 2018.
https://www.aclweb.org/anthology/N18-1197.pdf
The paper aims to show the benefit of using natural language strings as a parameter space. During training time, the model is trained to generate natural language descriptions of the task. During testing, these descriptions are geenrated automatically based on a small number of examples and the end performance on solving the task is evaluated.
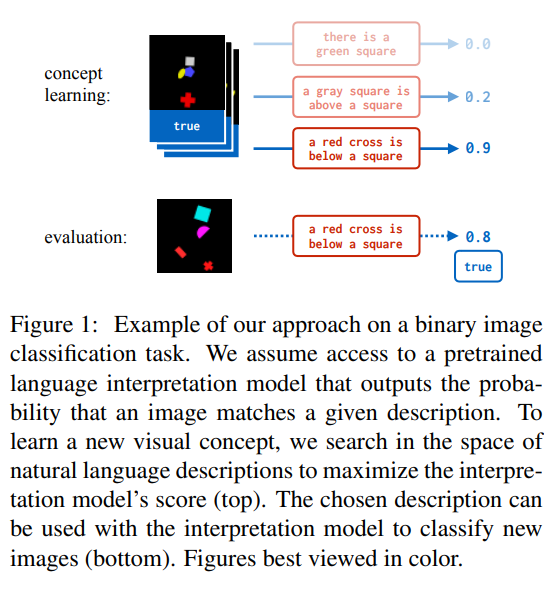
21. Robust Incremental Neural Semantic Graph Parsing
Jan Buys, Phil Blunsom. Oxford, Deepmind. ACL 2017.
https://www.aclweb.org/anthology/P17-1112.pdf
The paper describes a neural semantic graph parser. They combine an encoder-decoder architecture and a transition pased parser, with modifications to cover graphs as opposed to trees. Evaluation is done on Minimal Recursion Semantics (MRS) and Abstract Meaning Representation (AMR).
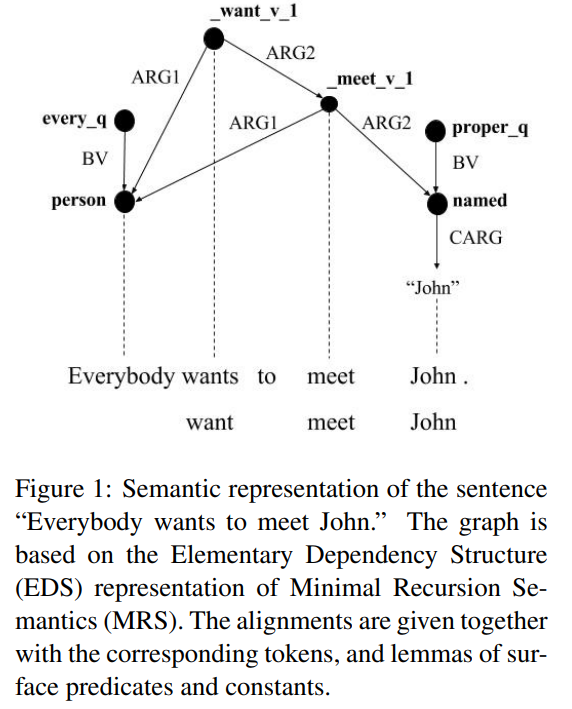
22. Adversarially Regularising Neural NLI Models to Integrate Logical Background Knowledge
Pasquale Minervini, Sebastian Riedel. UCL. CoNLL 2018.
https://www.aclweb.org/anthology/K18-1007.pdf
The paper describes a method for introducing adversarial examples into the process of training an NLI system. Five logical rules are listed, based on the definition of entailment. For example, a sentence should entail itself and contradiction should be symmetrical. Artificial adversarial sentences are then generated, by making changes to existing sentences in the dataset and making sure that the model gets a low score on these examples.
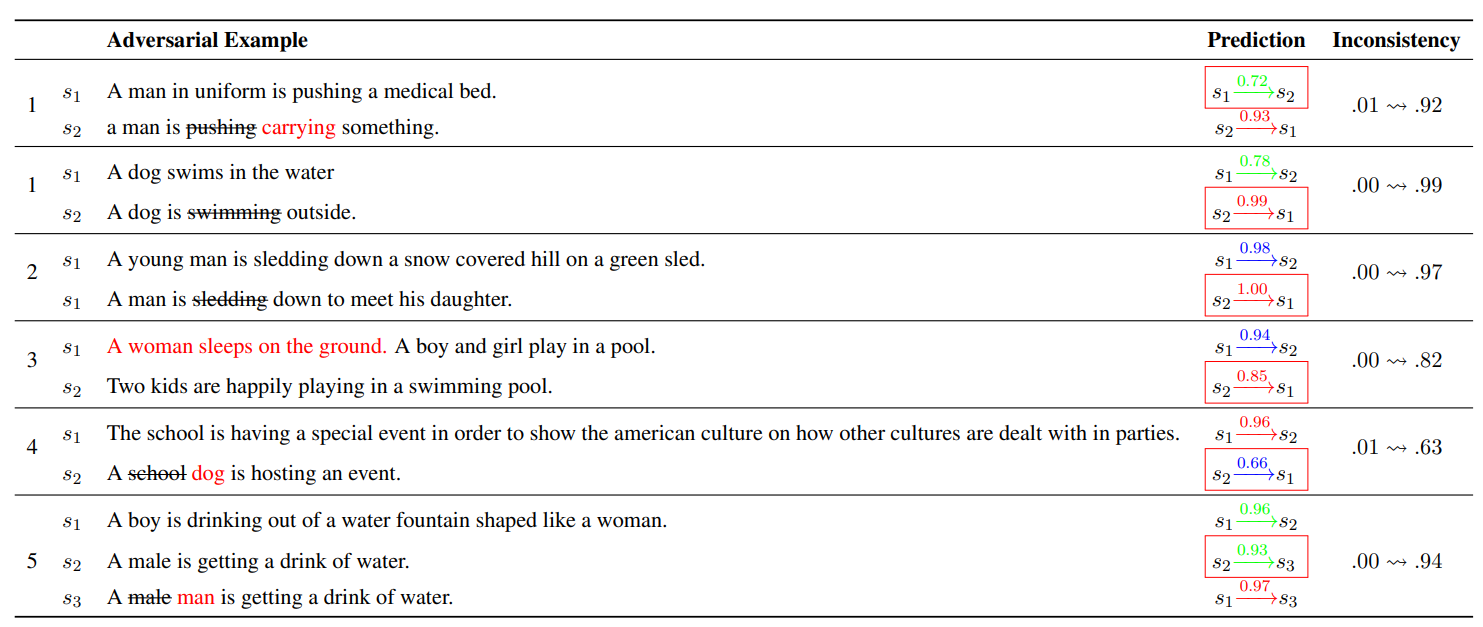
23. CAM: A Combined Attention Model for Natural Language Inference
Amit Gajbhiye, Sardar Jaf, Noura Al Moubayed, Steven Bradley, A. Stephen McGough. Durham, Newcastle. Big Data 2018.
https://ieeexplore.ieee.org/stamp/stamp.jsp?arnumber=8622057
The paper describes an architecture for the natural language inference (NLI) task where two levels of attention are combined. First, intra-attention where each sentence itself is used to attend to each of the words, then inter-attention where the attention weights are calculated based on the other sentence (premise vs hypothesis). Evaluation is performed on the SNLI and SciTail datasets.

24. Modeling Student Response Times: Towards Efficient One-on-one Tutoring Dialogues
Luciana Benotti, Jayadev Bhaskaran, Sigtryggur Kjartansson, David Lang. Cordoba, Stanford. W-NUT 2018.
https://www.aclweb.org/anthology/W18-6117.pdf
Predicting how long a student will take to answer a question from a tutor. They construct a new dataset of 18K tutoring session dialogues, covering math, chemistry and physics. Several baselines are reported, starting with a basic RNN and adding task-specific features.
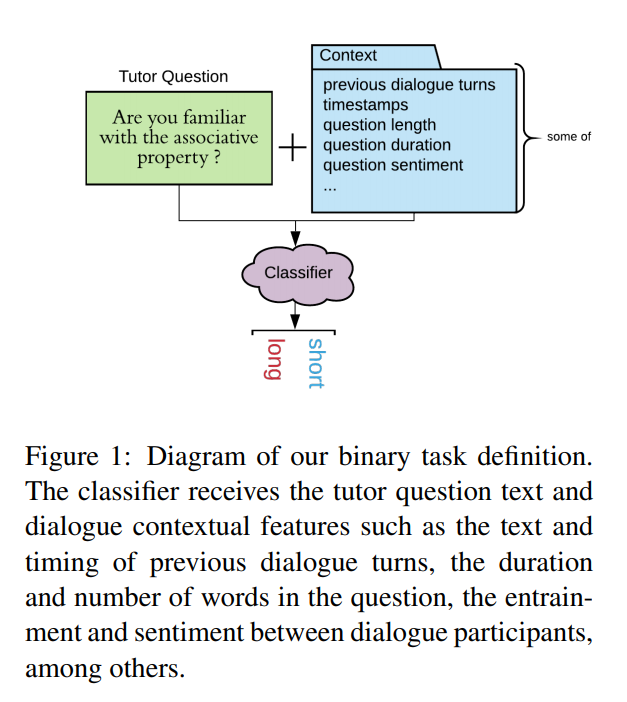
25. Retrieve and Re-rank: A Simple and Effective IR Approach to Simple Question Answering over Knowledge Graphs
Vishal Gupta, Manoj Chinnakotla, Manish Shrivastava. Hyderabad, Microsoft. FEVER 2018.
https://www.aclweb.org/anthology/W18-5504.pdf
The paper presents a neural model for question answering over knowledge graphs. The question and a tuple of the possible answer relation are mapped to a score and used to rerank the output of a simple term-based IR system. State-of-the-art results on the SimpleQuestions dataset are reported.
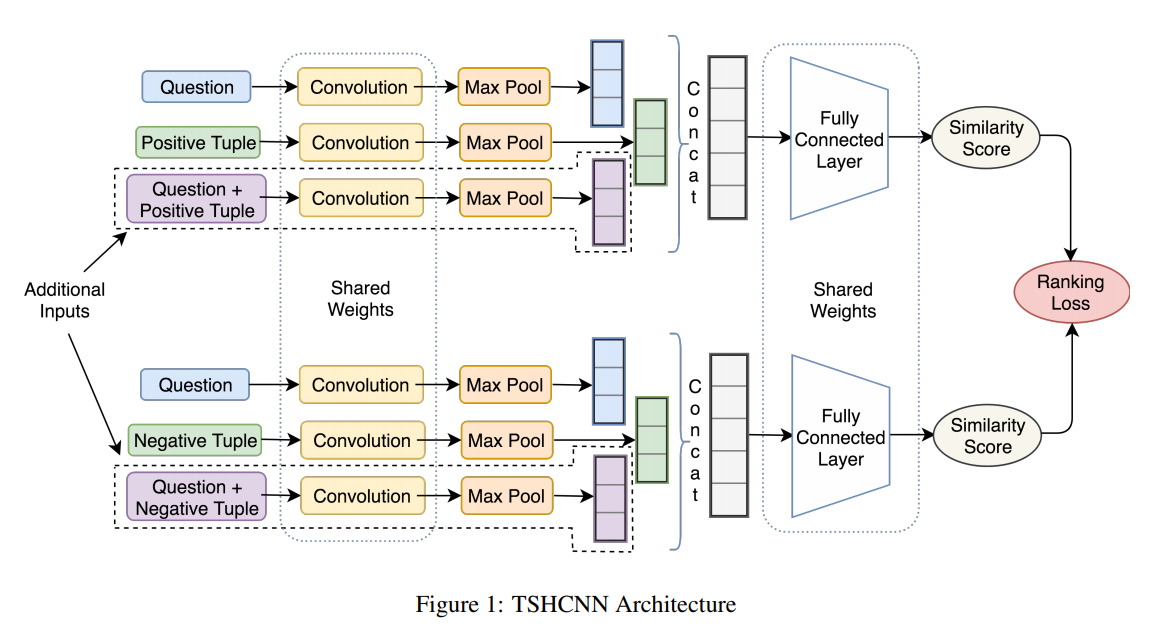
26. Dynamic Meta-Embeddings for Improved Sentence Representations
Douwe Kiela, Changhan Wang, Kyunghyun Cho. Facebook, NYU, CIFAR. EMNLP 2018.
https://www.aclweb.org/anthology/D18-1176.pdf
An architecture for using multiple types of pre-trained word embeddings in the same model. The different embeddings are mapped to a joint space and combined using attention, conditioned on the context. Evaluation is performed on NLI, sentiment detection adn image caption retrieval.
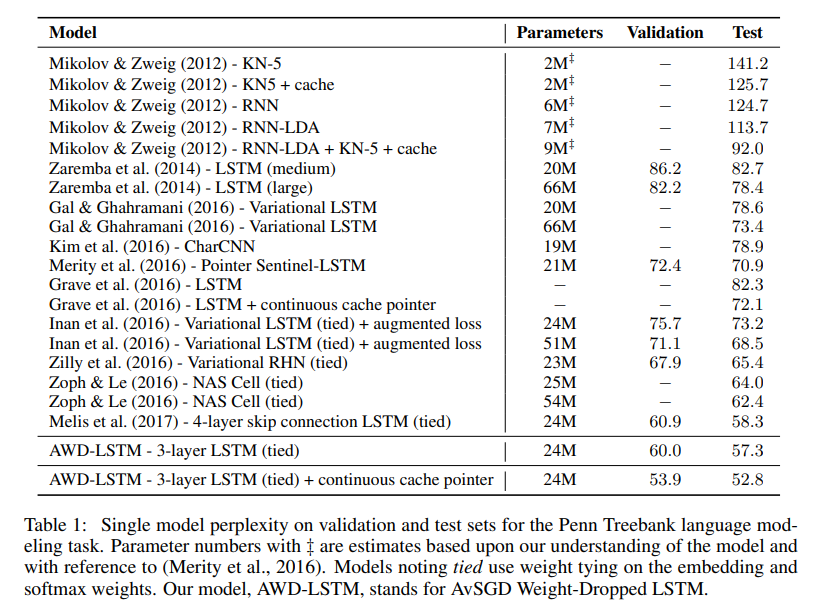
27. Regularizing and Optimizing LSTM Language Models
Stephen Merity, Nitish Shirish Keskar, Richard Socher. Salesforce. ICLR 2018.
https://openreview.net/pdf?id=SyyGPP0TZ
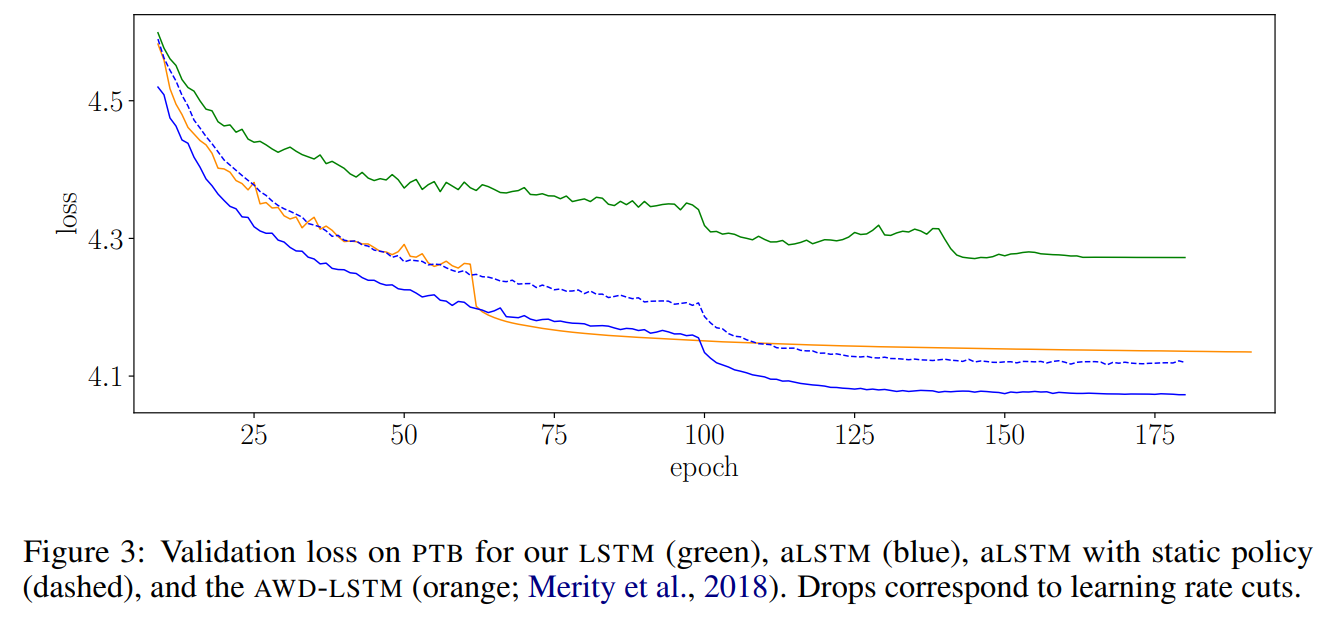
A series of modifications to a basic LSTM language model to achieve state-of-the-art performance. Dropout on hidden connection weights, optimizing with averaged SGD, variable-length backpropagation, variational dropout, dropping out whole words, tying embedding and output weights, regularization of hidden state activations, and a cache model. Evaluation on PTB and WikiText-2 achieves very low perplexities.
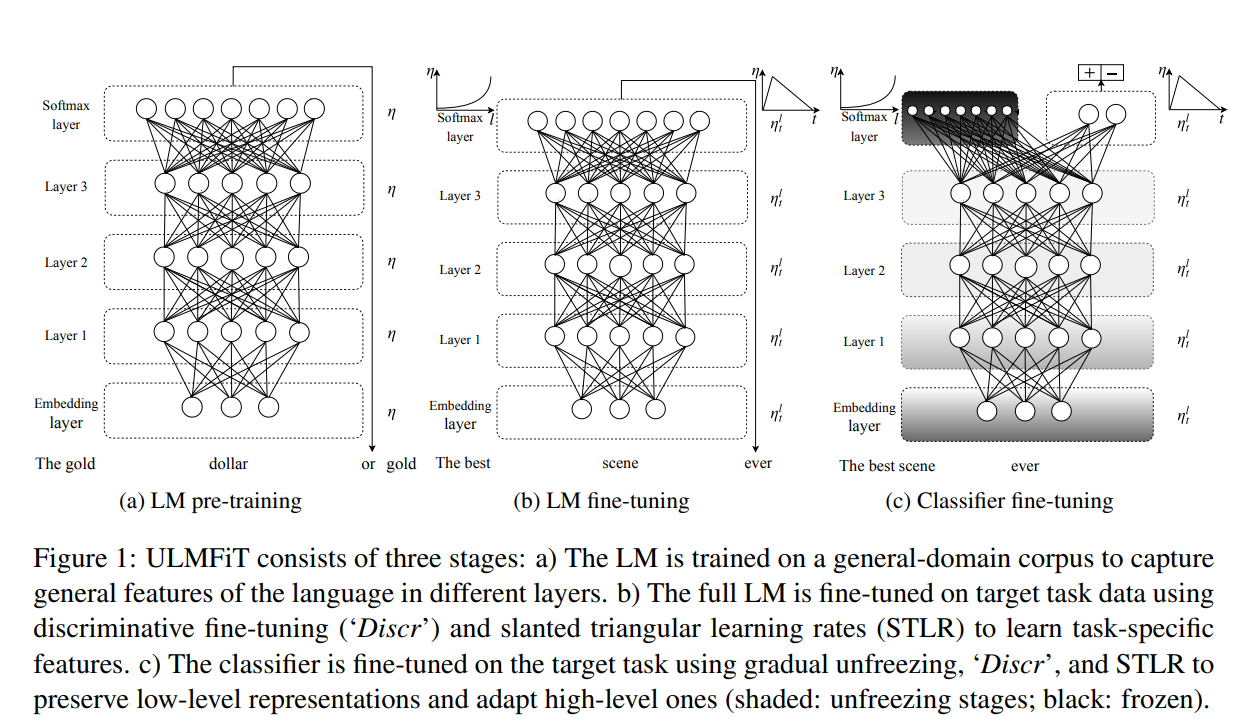
28. Universal Language Model Fine-tuning for Text Classification
Jeremy Howard, Sebastian Ruder. fast.ai, San Francisco, Insight, Aylien. ACL 2018.
https://www.aclweb.org/anthology/P18-1031.pdf
Pre-training a language model on large amounts of plain text, then fine-tuning it to work as a text classifier for a specific dataset. Strategies for controlling the learning rate and unfreezing different layers are introduced in order to prevent catastrophic forgetting. Achieves state-of-the art results on several datasets for sentiment analysis, question classification and topic classification.
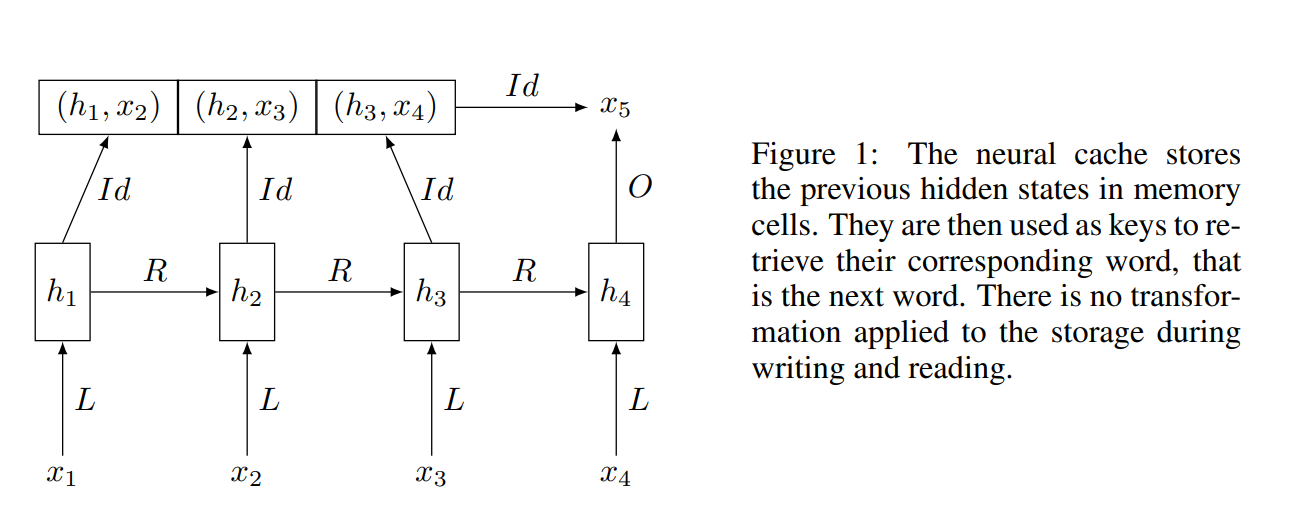
29. Improving Neural Language Models with a Continuous Cache
Edouard Grave, Armand Joulin, Nicolas Usunier. Facebook. ICLR 2017.
https://openreview.net/pdf?id=B184E5qee
A method for augmenting trained neural language models with a continuous cache system, biasing the model towards words that it has recently seen in the text. The hidden states from a number of previous timesteps are recorded, along with the actual next word after it is observed. At test time, a dot product between the current hidden state and all the recorded ones is used to calculate a second probability distribution for next word prediction, which is then interpolated with the regular language model.
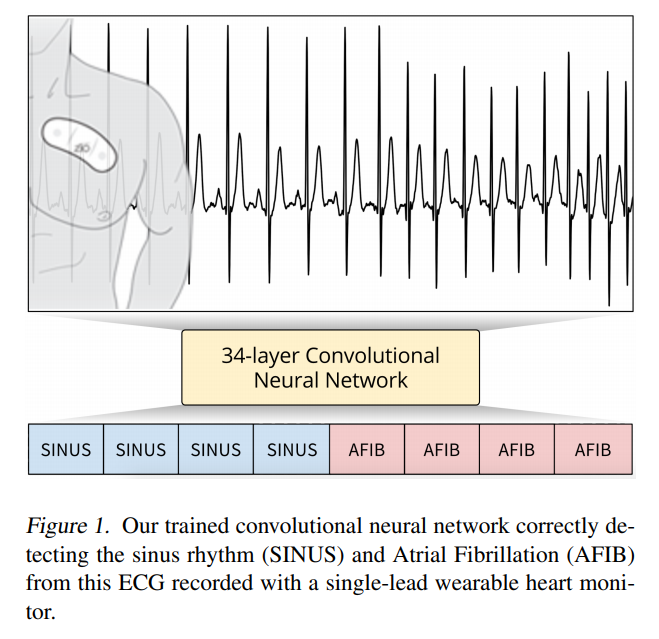
30. Cardiologist-Level Arrhythmia Detection with Convolutional Neural Networks
Awni Y. Hannun, Pranav Rajpurkar, Masoumeh Haghpanahi, Geoffrey H. Tison, Codie Bourn, Mintu P. Turakhia, Andrew Y. Ng. Stanford, IRhythm. ArXiv 2017.
https://arxiv.org/pdf/1707.01836.pdf
The paper describes a deep convolutional model for classifying cardiac arrhythmias based on ECG signals. They collect a large dataset of 30-second ECG recordings annotated for 12 different arrhythmias; unfortunately the data is not made public.
The model achieves better F1 score on most of the label, compared to individual human annotators.
31. Explainable Prediction of Medical Codes from Clinical Text
James Mullenbach, Sarah Wiegreffe, Jon Duke, Jimeng Sun, Jacob Eisenstein. Georgia Tech. NAACL 2018.
https://www.aclweb.org/anthology/N18-1100.pdf
A neural model for classifying the text in patient discharge summaries with one of 8,922 medical codes. The architecture uses a convolutional network over words, followed by an attention layer, where the attention weights are also used for providing an interpretaion of the classification. While training, the model is regularised to have similar model parameters for medical codes that have similar descriptions.

32. Learning Patient Representations from Text
Dmitriy Dligach, Timothy Miller. Loyola, Boston, Harvard. *SEM 2018.
https://www.aclweb.org/anthology/S18-2014.pdf
A model for learning to encode patient information into a useful vector representation. First, a text classifier is trained to take patient records as input and predict the diagnostic billing codes. This encoder is then applied on a different dataset for classifying discharge records for obesity and related conditions.
33. On the Limitations of Unsupervised Bilingual Dictionary Induction
Anders Søgaard, Sebastian Ruder, Ivan Vulić. Copenhagen, Insight, Aylien, Cambridge. ACL 2018.
https://www.aclweb.org/anthology/P18-1072.pdf
Investigating under which conditions bilingual dictionary induction actually works. They find that it requires 1) data from a comparable domain, 2) with embeddings trained using the same hyper-parameters, 3) using large monolingual corpora, and 4) only works on languages that use similar marking and typing. They also investigate using some supervision in the form of identically spelled words, which provides much more robust results.

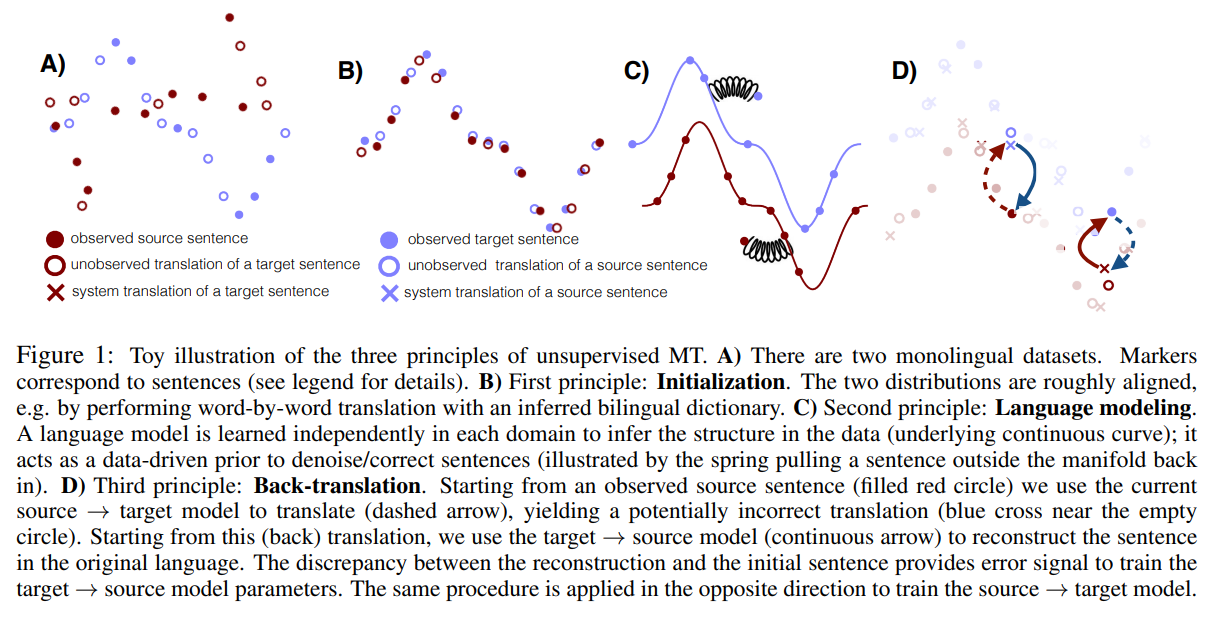
34. Phrase-Based & Neural Unsupervised Machine Translation
Guillaume Lample, Myle Ott, Alexis Conneau, Ludovic Denoyer, Marc’Aurelio Ranzato. Facebook, Le Mans, Sorbonne. EMNLP 2018.
https://www.aclweb.org/anthology/D18-1549.pdf
A more streamlined version of previous unsupervised machine translation work. The framework starts with cross-lingual embeddings (which are inferred without parallel data) and uses language modeling with iterative back-translation in order to train and improve the translation model. Both SMT and NMT are investigated, with SMT actually giving better results.
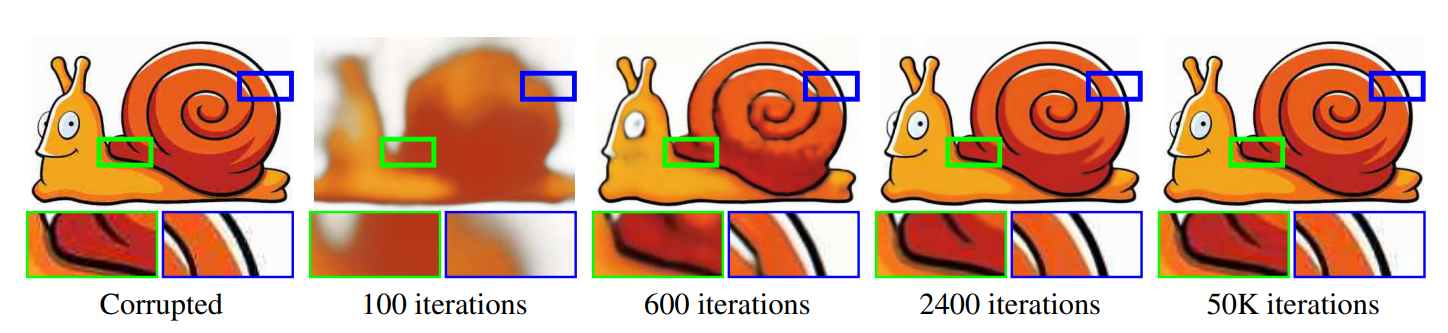
35. Deep Image Prior
Dmitry Ulyanov, Andrea Vedaldi, Victor Lempitsky. Yandex, Oxford, Skoltech. CVPR 2018.
https://arxiv.org/pdf/1711.10925.pdf
A network is trained to take a random vector as input and produce one specific image as output. As it learns to reconstruct this image, it can produce an “improved” version of that image, provided that it does not overtrain. The method is evaluated on tasks such as denoising, image superv-resolution and inpainting.
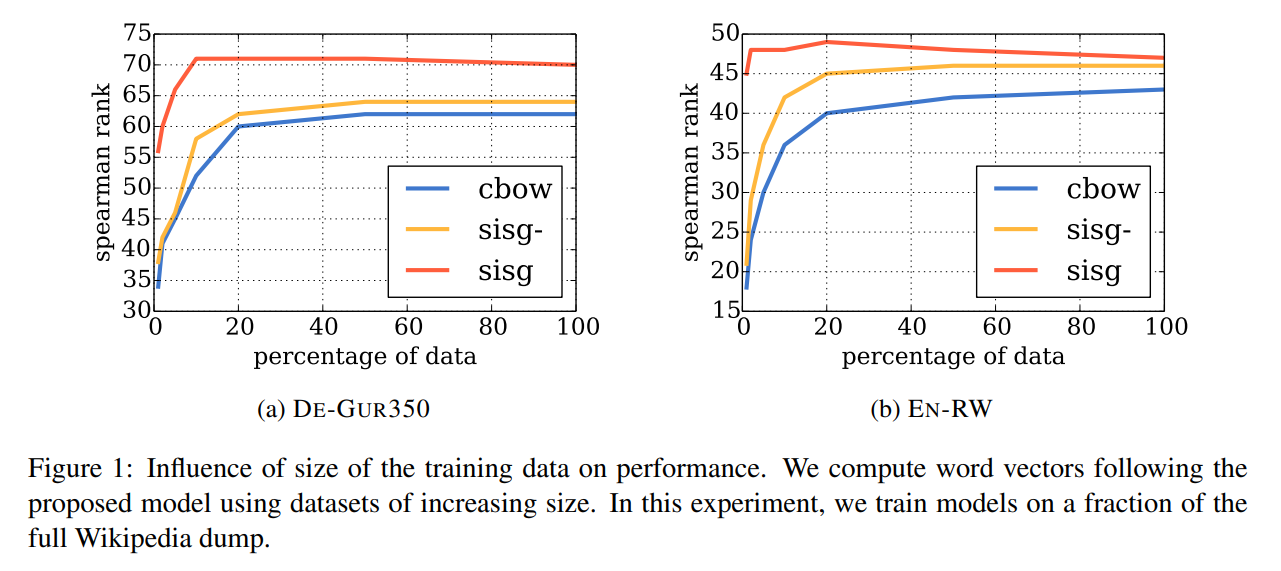
36. Enriching Word Vectors with Subword Information
Piotr Bojanowski, Edouard Grave, Armand Joulin, Tomas Mikolov. Facebook. TACL 2017.
https://www.aclweb.org/anthology/Q17-1010.pdf
The skip-gram model for word embeddings is extended with character-level information. Individual word embeddings are constructed by adding together embeddings for individual character n-grams, along with the main word embedding. They show good performance on word similarity and language modeling, particularly for morphologically rich languages or rare words.
37. Distributional Modeling on a Diet: One-shot Word Learning from Text Only
Su Wang, Stephen Roller, Katrin Erk. UTexas. IJCNLP 2017.
https://www.aclweb.org/anthology/I17-1021.pdf
Bayesian models for learning to predict properties of new words, after having observed them only once. The model is trained using concrete nouns and their lists of known properties, and then learns latent topics that can generate both word contexts (eg dependency relations) and the properties. They evaluate as a ranking problem on datasets with annotated properties.
38. Differentiable plasticity: training plastic neural networks with backpropagation
Thomas Miconi, Jeff Clune, Kenneth O. Stanley. Uber. ICML 2018.
http://proceedings.mlr.press/v80/miconi18a/miconi18a.pdf
Proposes a neural connection that in addition to regular learnable weights includes plasticity. The activation of a neuron depends on the Hebbian trace of the previous activations, while the internal weight for this component is also learned. Improves performance at tasks that test memorization of patterns and images.
39. Neural Character-based Composition Models for Abuse Detection
Pushkar Mishra, Helen Yannakoudakis, Ekaterina Shutova. Cambridge, Amsterdam. ALW2 2018.
https://www.aclweb.org/anthology/W18-5101.pdf
Investigation of character-based neural architectures for detecting abusive language. They evaluate 10 different model variants on Twitter and Wikipedia datasets. The proposed model predicts word embeddings for unseen and obfuscated words based on character-level input from the word and its context.
40. Breaking the Activation Function Bottleneck through Adaptive Parameterization
Sebastian Flennerhag, Hujun Yin, John Keane, Mark Elliot. Manchester, Turing. NeurIPS 2018.
https://papers.nips.cc/paper/8000-breaking-the-activation-function-bottleneck-through-adaptive-parameterization.pdf
Proposing an adaptive feed-forward layer module. Regular activation functions are replaced with parameterized versions that are calculated based on the input. Demonstrating improvement on MNIST and language modeling.
41. Towards Robust Interpretability with Self-Explaining Neural Networks
David Alvarez-Melis, Tommi S. Jaakkola. MIT. NeurIPS 2018.
https://papers.nips.cc/paper/8003-towards-robust-interpretability-with-self-explaining-neural-networks.pdf
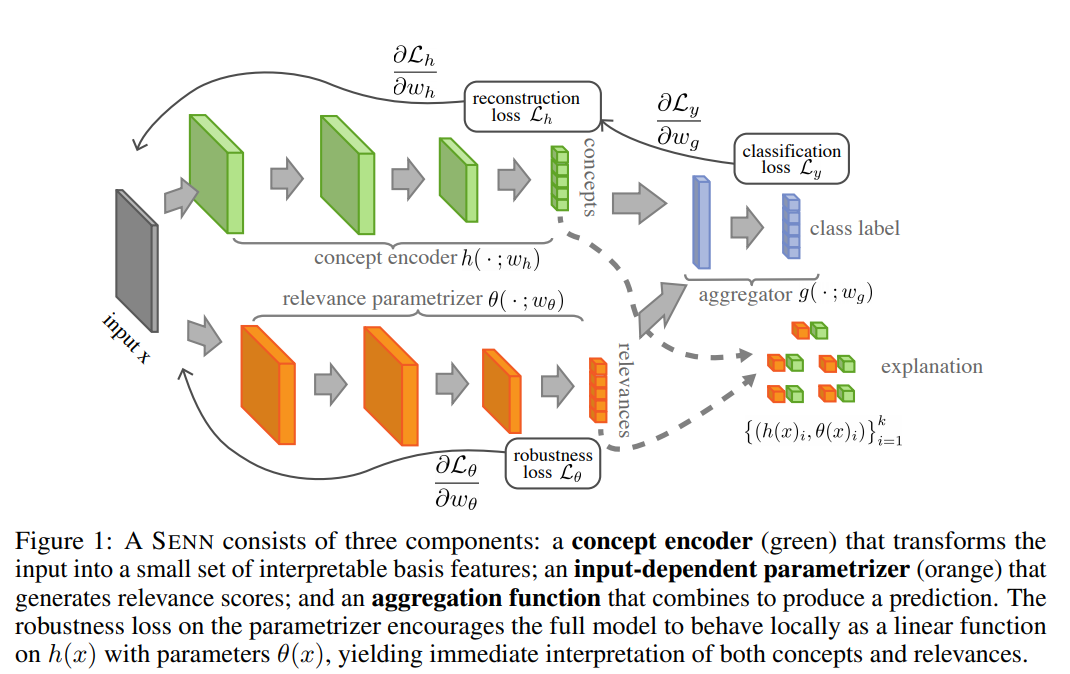
Defines three desiderata for interpretable machine learning models: easy to understand, faithful to model decision, and locally stable around a given datapoint. Based on these properties, a model class is proposed that takes them into account. An explicit regularization term is introduced, training the model to have stable outputs around a specific input.
42. Axiomatic attribution for deep networks
Mukund Sundararajan, Ankur Taly, Qiqi Yan,
https://arxiv.org/pdf/1703.01365.pdf
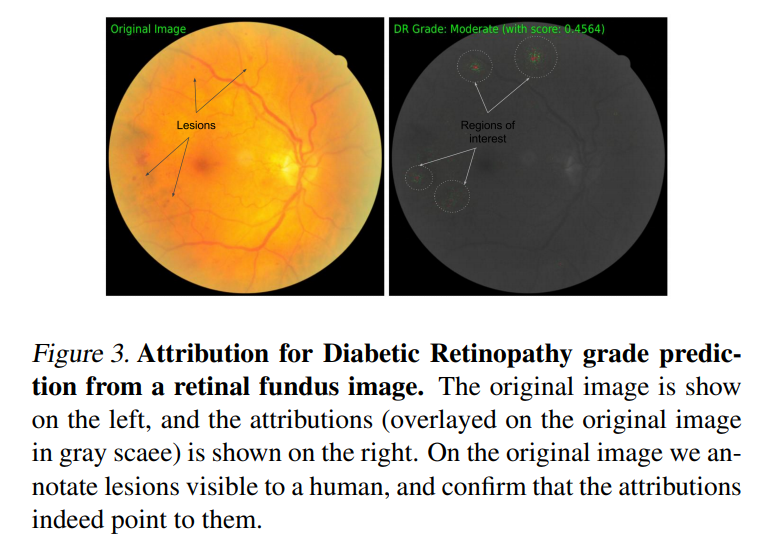
Proposes a novel method for attributing network predictions to individual input features, called Integrated Gradients. The gradient values are measured at various points along a path, starting with a neutral input (e.g. a black image) and moving towards a real input vector. These are then summed and multiplied by the difference in feature values, giving the attribution weight for a each specific feature position.
43. Deep Neuroevolution: Genetic Algorithms Are a Competitive Alternative for Training Deep Neural Networks for Reinforcement Learning
Felipe Petroski Such, Vashisht Madhavan, Edoardo Conti, Joel Lehman, Kenneth O. Stanley, Jeff Clune. Uber. Deep RL 2018.
https://arxiv.org/pdf/1712.06567.pdf
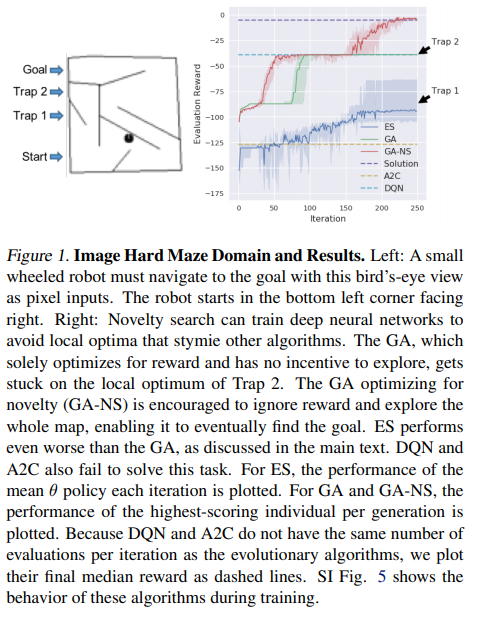
Experiments with a genetic algorithm for training neural networks to play Atari games. A deep network with 4M+ parameters is mutated by adding random noise to the parameters, the resulting networks are evaluated and 1000 best configurations are kept for the next iteration.
The genetic algorithm achieves higher or comparable results to Q-learning and policy gradients on several games.
44. Multi-Task Learning as Multi-Objective Optimization
Ozan Sener, Vladlen Koltun. Intel. NeurIPS 2018.
https://arxiv.org/pdf/1810.04650.pdf
A method for using adaptive weights for different loss functions when optimizing multiple objectives. After calculating the gradients, a separate function is minimized in order to find better weights. The method is shown to give a Pareto optimal solution and improves performance on several multi-task vision datasets.
45. Predictive Uncertainty Estimation via Prior Networks
Andrey Malinin, Mark Gales. Cambridge. NeurIPS 2018.
https://arxiv.org/pdf/1802.10501.pdf
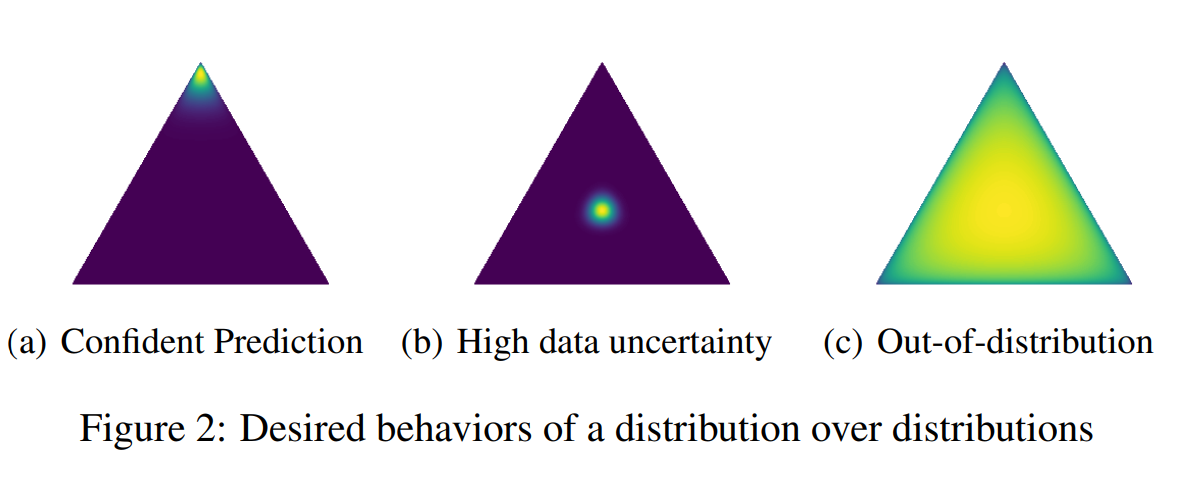
A network that is able to quantify how uncertain it is when classifying specific datapoints. The model is constructed to parameterize a Dirichlet distribution, and it is directly optimized to predict a flat distribution for out-of-distribution examples. Evaluation is performed on the tasks of detecting misclassifications and out-of-domain examples.
46. Co-Attention Based Neural Network for Source-Dependent Essay Scoring
Haoran Zhang, Diane Litman. Pittsburgh. BEA 2018.
https://www.aclweb.org/anthology/W18-0549v2.pdf
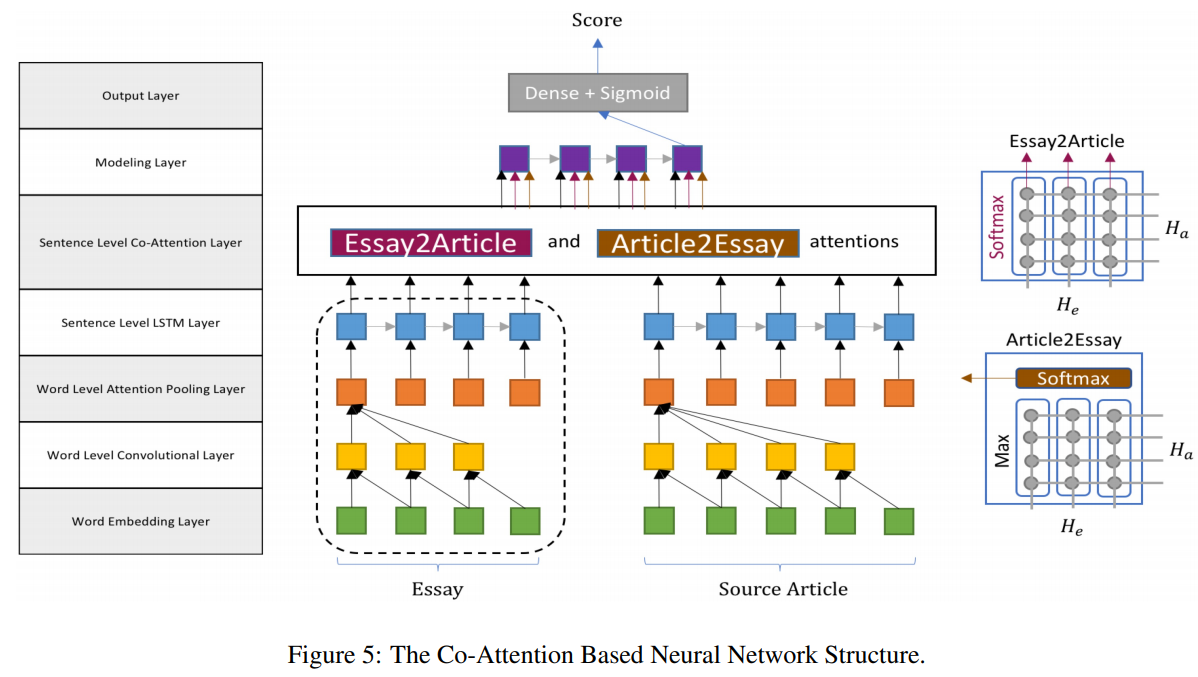
The paper presents a neural architecture for scoring essays that are written based on a source article. Both the article and the resulting essay are encoded into sentence representations, an attention mechanism is applied to these sentences in both directions, and a final essay score is predicted for an article-essay pair. Evaluation is performed on the subsets of datasets that have reference articles available.
47. Relational recurrent neural networks
Adam Santoro, Ryan Faulkner, David Raposo, Jack Rae, Mike Chrzanowski, Theophane Weber, Daan Wierstra, Oriol Vinyals, Razvan Pascanu, Timothy Lillicrap. DeepMind, CoMPLEX. NeurIPS 2018.
https://arxiv.org/pdf/1806.01822.pdf
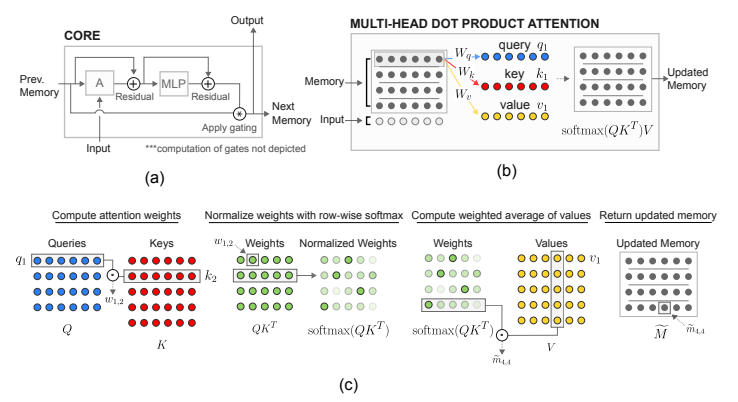
Introduces the Relational Memory Core, an architecture for storing and modifying distributed memory cells in RNNs. At each step, multi-head self-attention is performed over all the memory cells, along with the input at the current time step, producing an updated versions of the full memory. The model is applied to Pacman, language modeling, program evaluation and a synthetic task for finding the Nth farthest input vector.
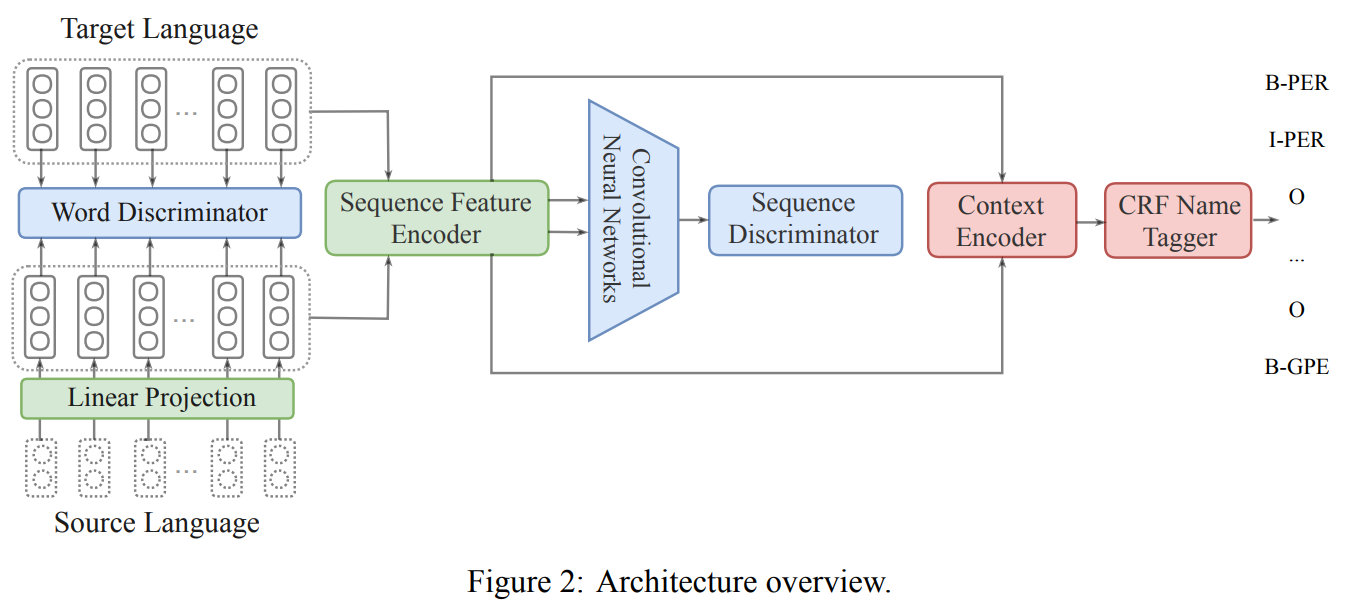
48. Cross-lingual Multi-Level Adversarial Transfer to Enhance Low-Resource Name Tagging
Lifu Huang, Heng Ji, Jonathan May. Rensselaer, USC. NAACL 2019.
https://www.aclweb.org/anthology/N19-1383.pdf
The paper describes a model for multilingual named entity recognition, where language amounts of annotated data in a source language is used to improve performance in the target language. First, monolingual word embeddings are mapped into the same space using an adversarial objective. These are then given to a Bi-LSTM that predicts NER labels, while also being trained with the adversarial language detection objective.
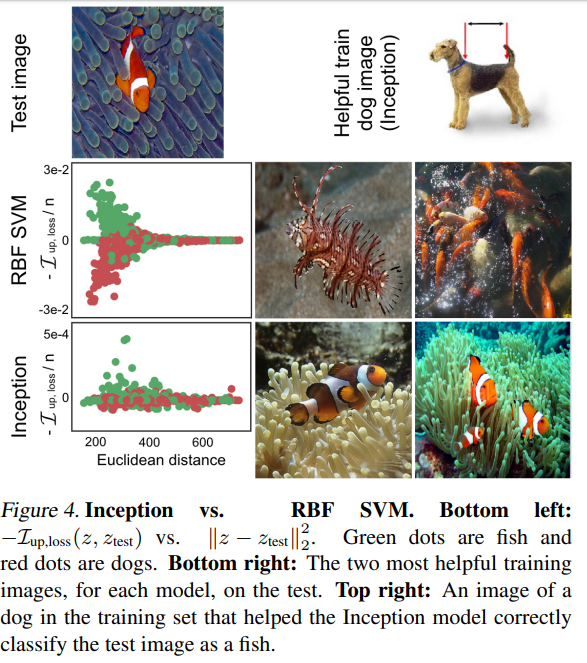
49. Understanding Black-box Predictions via Influence Functions
Pang Wei Koh, Percy Liang. Stanford. ICML 2017.
http://proceedings.mlr.press/v70/koh17a/koh17a.pdf
Proposing the use of influence functions for interpreting the predictions of deep neural networks. The method calculates the gradient with respect to specific training images, thereby pointing out which training points are most responsible for a prediction on a particular test instance. They also describe a method of using this gradient to create imperceptible adversarial modifications in the training set, such that the model makes a mistake on a particular test image.
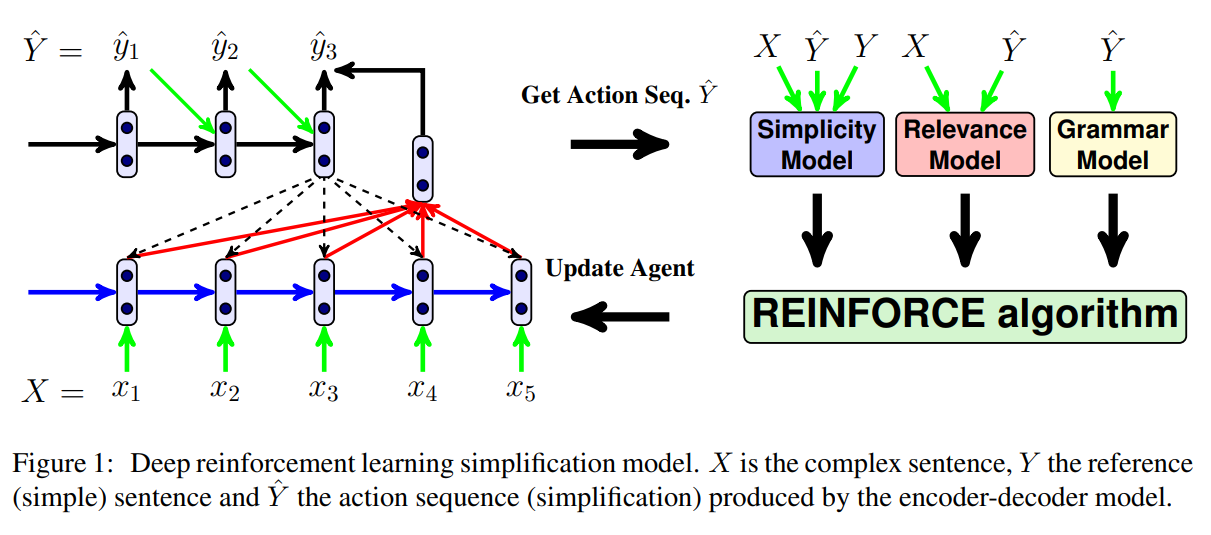
50. Sentence Simplification with Deep Reinforcement Learning
Xingxing Zhang, Mirella Lapata. Edinburgh. EMNLP 2017.
https://www.aclweb.org/anthology/D17-1062.pdf
Trains a sequence-to-sequence model for sentence simplification using reinforcement learning. The loss combines metrics for simplicity, relevance and fluency, and is non-differentiable, which is why the REINFORCE algorithm is used for training. They evaluate on several simplification datasets and make their code available, along with the system output.
51. Insertion Transformer: Flexible Sequence Generation via Insertion Operations
Mitchell Stern, William Chan, Jamie Kiros, Jakob Uszkoreit. Google, Berkeley. ArXiv 2019.
https://arxiv.org/pdf/1902.03249.pdf
The paper describes a modification of the transformer architecture for generation, where tokens can be generated out of order.
At each step, the transformer takes a partial sequence as input and predicts words that should be inserted into that sequence, along with the positions of where they should be inserted.
This process is iteratively repeated until end tokens are generated, either for each slot or for the whole sequence.
The model is evaluated on the WMT 2014 English-German dataset, with the proposed architecture performing comparably to the left-to-right transformer and the blockwise parallel model.

52. Area Attention
Yang Li, Lukasz Kaiser, Samy Bengio, Si Si. Google. ICML 2019.
http://proceedings.mlr.press/v97/li19e/li19e.pdf
The paper describes a modification to attention where the model is able to attend to collections of items in addition to individual items.
The keys and values of nearby items are combined in a grid, in order to create these new collections, which are then included as choices in the regular attention mechanism.
Evaluation is performed on machine translation and image captioning datasets, by modifying the existing transformer or LSTM architectures with this type of attention.

53. Evaluating neural network explanation methods using hybrid documents and morphosyntactic agreement
Nina Poerner, Hinrich Schütze, Benjamin Roth. Munich. ACL 2018.
https://www.aclweb.org/anthology/P18-1032.pdf
Proposes two artificial tasks in order to evaluate different methods of explaining the decisions of neural networks in text classification. Also proposes a new explanation method based on LIME that is more suited to text classification that requires context. Performs an evaluation across a number of different classifier architectures and explanation methods.

54. Corpora Generation for Grammatical Error Correction
Jared Lichtarge, Chris Alberti, Shankar Kumar, Noam Shazeer, Niki Parmar, Simon Tong. Google. NAACL 2019.
https://arxiv.org/pdf/1904.05780.pdf
The paper investigates methods for generating parallel data for grammatical error correction systems. The methods include extracting examples from Wikipedia edit histories, backtranslation through a different language, randomly inserting spelling errors and inserting frequently occurring errors. Iterative correction, repeatedly passing the output through the correction system, is also shown to help.
55. A single-layer RNN can approximate stacked and bidirectional RNNs, and topologies in between
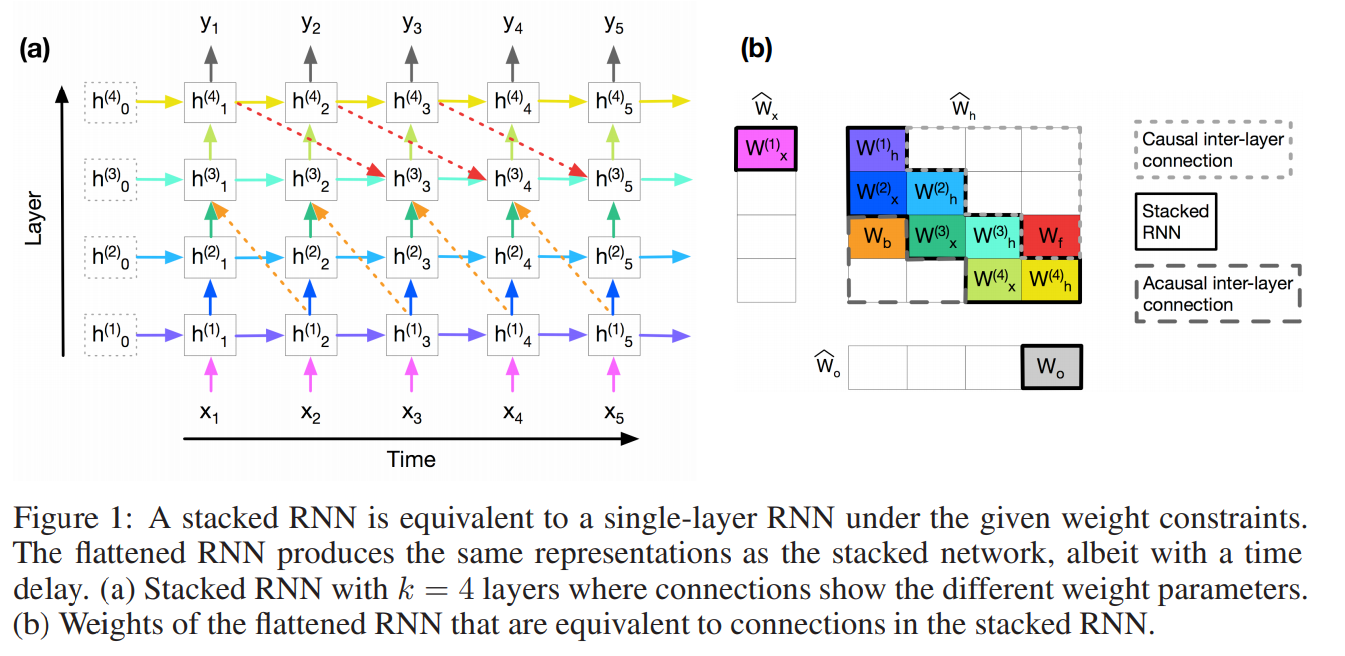
Javier S. Turek, Shailee Jain, Mihai Capota, Alexander G. Huth, Theodore L. Willke. Intel, UTexas. ArXiv 2019.
https://arxiv.org/pdf/1909.00021.pdf
The paper investigates how a single-layer RNN or LSTM can approximate multi-layer and bi-directional RNN/LSTM architectures.
This is achieved through delaying the output from the RNN, which allows the model to replace the depth in layers with depth in time steps.
The bidirectionality aspect can also be approximated, if the delay is large enough and the RNN is exposed to the necessary number of input steps before starting to produce output.
Evaluation is performed on two synthetic datasets and on the task of part-of-speech tagging.
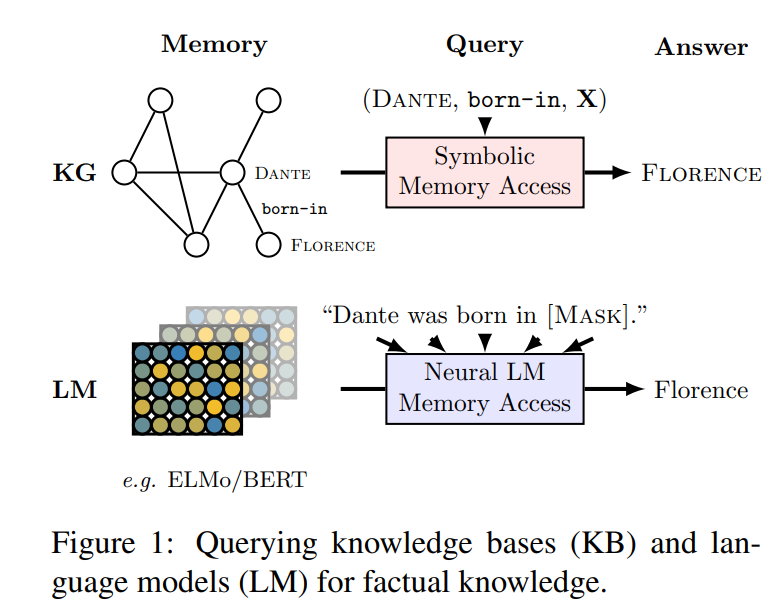
56. Language Models as Knowledge Bases?
Fabio Petroni, Tim Rocktäschel, Patrick Lewis, Anton Bakhtin, Yuxiang Wu, Alexander H. Miller, Sebastian Riedel. Facebook, UCL. ArXiv 2019.
https://arxiv.org/pdf/1909.01066.pdf
Investigates the use of language models for question answering. The questions are formulated as fill-in-the-blank cloze sentences and the language model has to fill in the answer.
They find that BERT-large is surprisingly competitive against supervised knowledge bases and relation extractors, although the performance does depend on the type of question.
57. Still not systematic after all these years: On the compositional skills of sequence-to-sequence recurrent networks
Brenden Lake, Marco Baroni. Facebook. ArXiv 2017.
https://openreview.net/pdf?id=H18WqugAb
Experiments on synthetic data on the learning abilities of seq2seq models. The results show that the RNN/LSTM models have difficulty in learning to compose, for example based on shorter sequences. Also, their composition skills can be unintuitive, sometimes failing on a simpler case and succeeding on a more difficult one.
58. HellaSwag: Can a Machine Really Finish Your Sentence?
Rowan Zellers, Ari Holtzman, Yonatan Bisk, Ali Farhadi, Yejin Choi. Allen School, Allen Institute. ArXiv 2019.
https://arxiv.org/pdf/1905.07830.pdf
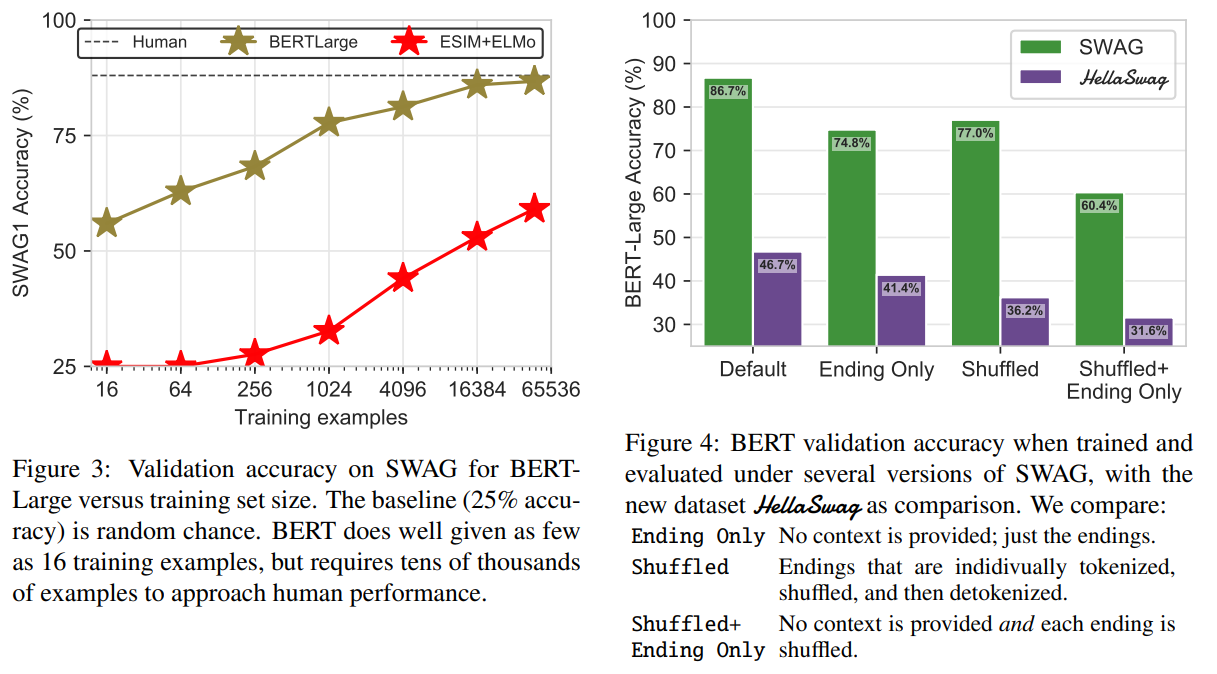
Creates a dataset for choosing the right last sentence in a text, specifically designed to be difficult for BERT. Performance on the existing SWAG dataset is high even if BERT does not see the context, or when the words in the candidate sentences are shuffled. To make a task where BERT does not perform as well, they take existing paragraphs from ActivityNet and WikiHow, generate candidates from GPT and explicitly exclude those that BERT guesses easily.
59. Topic Modeling in Embedding Spaces
Adji B. Dieng, Francisco J. R. Ruiz, David M. Blei. Columbia, Cambridge. ArXiv 2019.
https://arxiv.org/pdf/1907.04907.pdf
Extending Latent Dirichlet Allocation with distributed embeddings of words and topics. The probability of a word belonging to a particular topic is calculated as the dot product of their embeddings, resulting in words and topics being in the same space. Evaluation is performed by measuring topic coherence and topic diversity, finding that the proposed model outperforms LDA and NVDM.

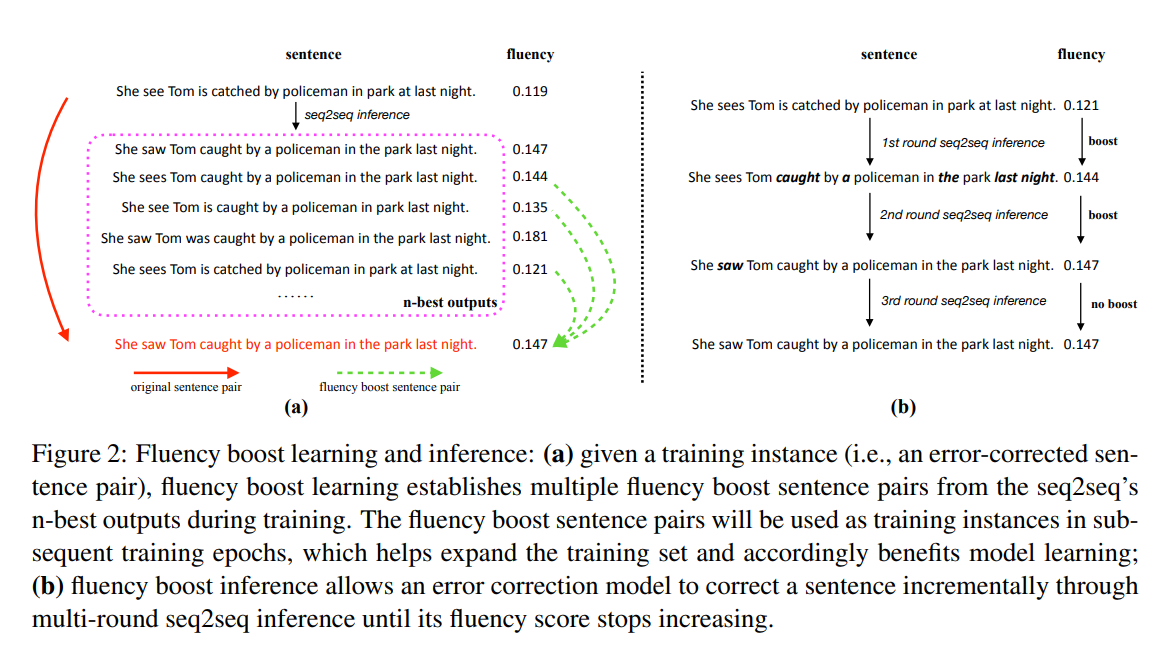
60. Fluency Boost Learning and Inference for Neural Grammatical Error Correction
Tao Ge, Furu Wei, Ming Zhou. Microsoft. ACL 2018.
https://www.aclweb.org/anthology/P18-1097.pdf
The paper describes a pipeline for grammatical error correction. Artificial error examples are generated through machine translation and filtered using a language model. At inference time, each sentence will be passed through the same system multiple times until the fluency score from a language model no longer improves.
61. Neural Multi-task Learning in Automated Assessment
Ronan Cummins, Marek Rei. Cambridge. ArXiv 2018.
https://arxiv.org/pdf/1801.06830.pdf
Investigating a multi-task architecture for essay scoring. While the model learns to predict a score for the overall essay, it is also optimized to perform error detection on the token level. Evaluation on the FCE dataset shows that provides small improvements for the error detection task and substantial improvements for the essay scoring task.
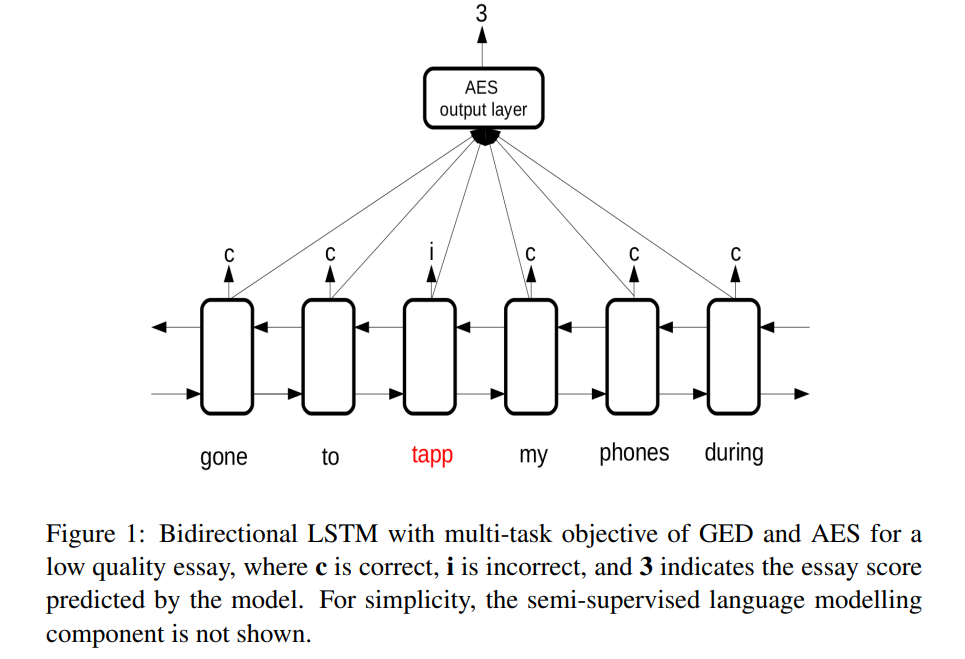
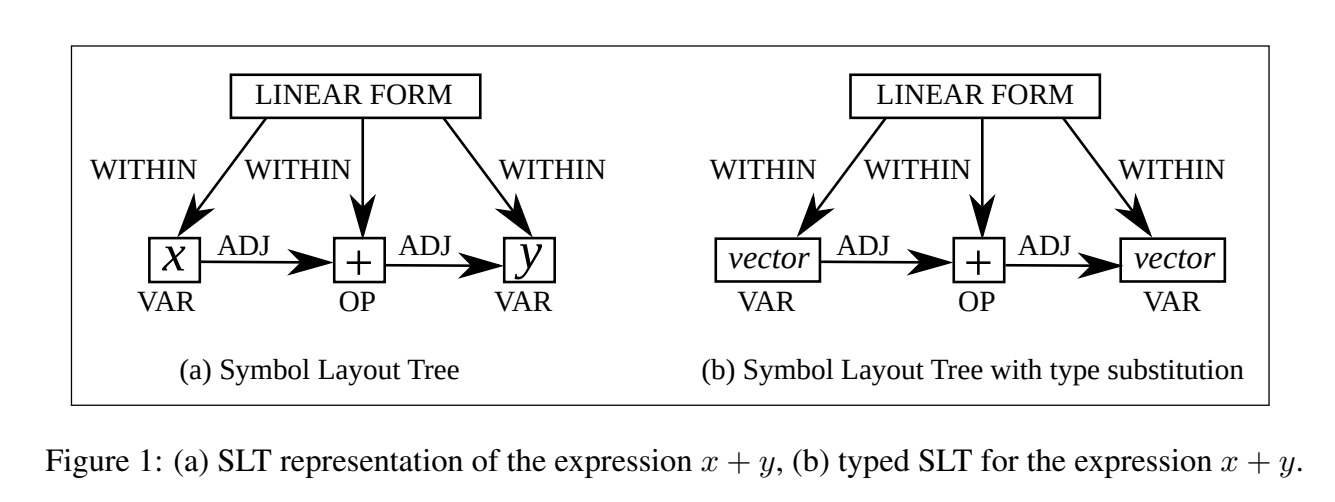
62. Variable Typing: Assigning Meaning to Variables in Mathematical Text
Yiannos Stathopoulos, Simon Baker, Marek Rei, Simone Teufel. Cambridge. NAACL 2018.
https://www.aclweb.org/anthology/N18-1028.pdf
Learning to assign type relations to variables in mathematical text. The target variable is designated in the input and a neural sequence labeling model is used to identify the tokens that refer to its type. Evaluation on a novel dataset shows that the tagging model outperforms a traditional SVM approach and a convnet architecture.
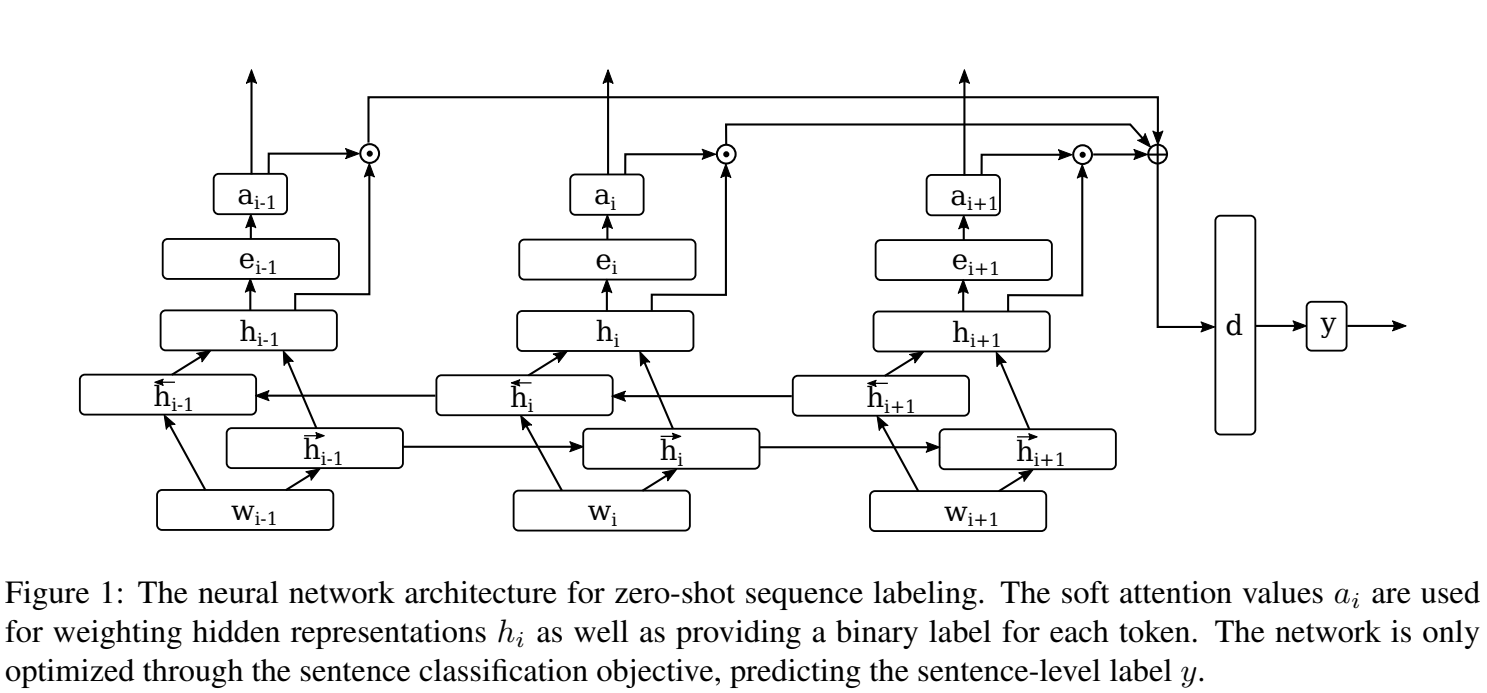
63. Zero-Shot Sequence Labeling: Transferring Knowledge from Sentences to Tokens
Marek Rei, Anders Søgaard. Cambridge, Copenhagen. NAACL 2018.
https://www.aclweb.org/anthology/N18-1027.pdf
Proposing a sentence classification model that learns to assign labels to individual tokens without any token-level supervision. A modified version of attention and a tied loss function is used to encourage the model to return distrete token labels. Evaluation is performed on hedge detection, error detection and sentiment detection, with the performance being surprisingly competitive to a fully-supervised model.
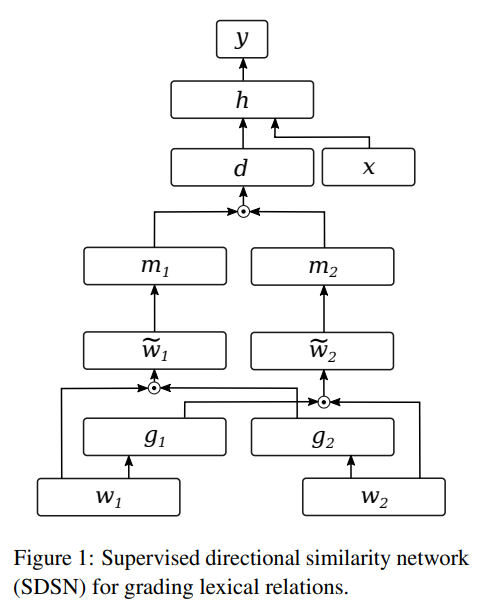
64. Scoring Lexical Entailment with a Supervised Directional Similarity Network
Marek Rei, Daniela Gerz, Ivan Vulić. Cambridge. ACL 2018.
https://www.aclweb.org/anthology/P18-2101.pdf
A supervised network for classifying directional relations between word pairs. The input word embeddings are mutually gated, mapped to a new space, then compared through a dot product in order to predict a score. Achieves state-of-the-art performance on the HyperLex and HypeNet datasets for hyponym detection.
65. Sequence Classification with Human Attention
Maria Barrett, Joachim Bingel, Nora Hollenstein, Marek Rei, Anders Søgaard. Copenhagen, Zurich, Cambridge. CoNLL 2018.
https://www.aclweb.org/anthology/K18-1030.pdf
Improving text classification by teaching the model to behave more like a human. An internal attention component is explicitly trained to assign attention weights proportional to the attention of human subjects, based on a gaze recording dataset. Experiments show general improvement on detecting sentiment, grammatical errors and hatespeech.
66. Advance Prediction of Ventricular Tachyarrhythmias using Patient Metadata and Multi-Task Networks
Marek Rei, Joshua Oppenheimer, Marek Sirendi. Transformative, Cambridge, Washington. ML4H 2018.
https://arxiv.org/pdf/1811.12938.pdf
Model architecture for predicting ventricular tachyarrhythmias in advance, based on heartbeat intervals. A number of time series features are given as input to the network, along with patient-level metadata, and the model is optimized to predict VT along with some patient properties. Evaluation on a publicly available dataset shows 77% precision and 71% recall.
67. Jointly Learning to Label Sentences and Tokens
Marek Rei and Anders Søgaard. Cambridge, Copenhagen. AAAI 2019.
https://arxiv.org/pdf/1811.05949.pdf
Investigating a model for joint supervision between text classification and sequence labeling. An attention function is used to construct sentence representations from individual words, which is then explicitly supervised with information from token-level labels. Evaluation on hedge detection, error detection and sentiment detection shows substantial improvements for both sentences and tokens.
68. A Simple and Robust Approach to Detecting Subject-Verb Agreement Errors
Simon Flachs, Ophélie Lacroix, Marek Rei, Helen Yannakoudakis, Anders Søgaard. Siteimprove, Copenhagen, Cambridge. NAACL 2019.
https://www.aclweb.org/anthology/N19-1251.pdf
Investigating systems for detecting subject-verb agreement errors, through the use of artificial data. Additional training examples are generated using a rule-based system, POS-tagging the text and replacing verbs with the incorrect inflections. Different models are compared and a neural sequence labeler trained on the artificial data is found to have the best performance.

69. CAMsterdam at SemEval-2019 Task 6: Neural and graph-based feature extraction for the identification of offensive tweets
Guy Aglionby, Chris Davis, Pushkar Mishra, Andrew Caines, Helen Yannakoudakis, Marek Rei, Ekaterina Shutova, Paula Buttery. Cambridge, Facebook, Amsterdam. SemEval 2019.
https://www.aclweb.org/anthology/S19-2100.pdf
A hybrid system for detecting offensive messages on Twitter. Neural text representations are given to a GBDT for classification, along with hierarchical labels and graph-based representations. Evaluation on the SemEval 2019 dataset achieves 84.7% accuracy.
70. Context is Key: Grammatical Error Detection with Contextual Word Representations
Samuel Bell, Helen Yannakoudakis, Marek Rei. Cambridge. BEA 2019.
https://www.aclweb.org/anthology/W19-4410.pdf
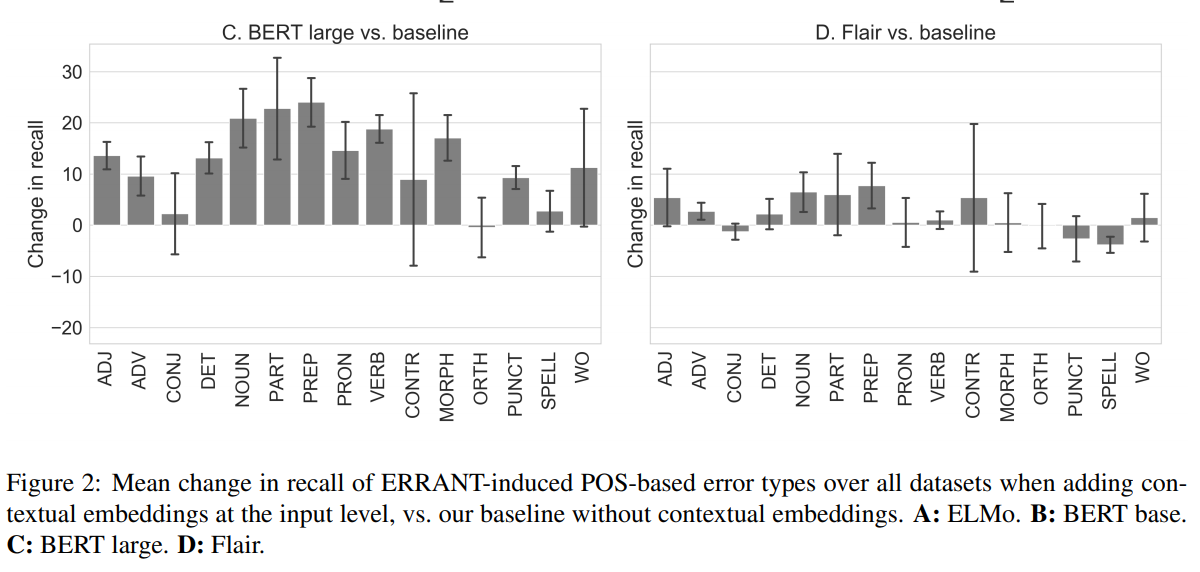
Investigating different contextual word representations for grammatical error detection. Flair, ELMo and BERT all provide an improvement, but combining BERT-large with the existing best error detection system gives a new state-of-the-art performance. Analysis shows large improvements on nouns, particles and preposition errors, but weaker performance on error types that are less likely to occur in general-purpose corpora, such as conjugation and orthography.
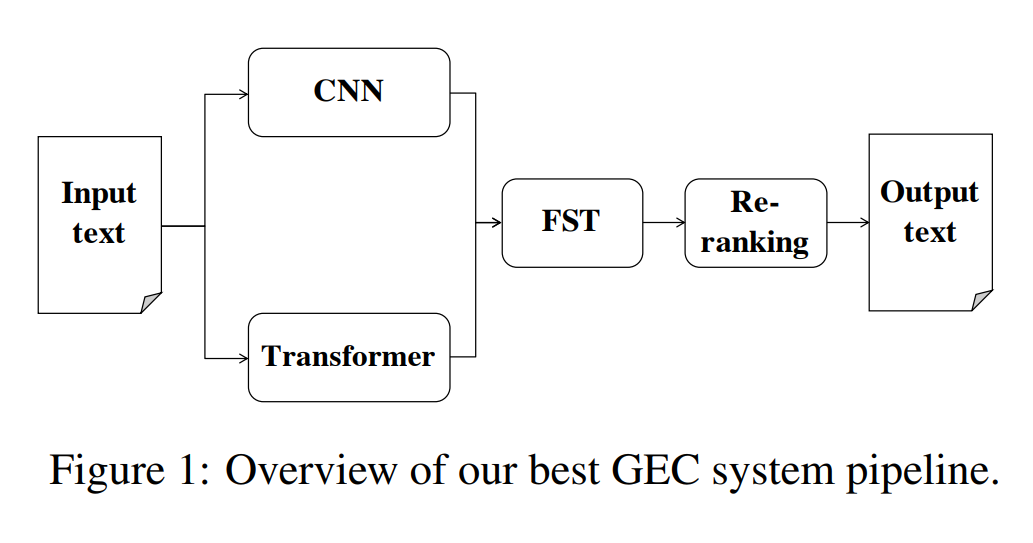
71. Neural and FST-based approaches to grammatical error correction
Zheng Yuan, Felix Stahlberg, Marek Rei, Bill Byrne, Helen Yannakoudakis. Cambridge. BEA 2019.
https://www.aclweb.org/anthology/W19-4424.pdf
A pipeline system for grammatical error correction. The output of two machine traslation systems is combined using a finite state transducer and a language model, then reranked based on the output of an error detection system. The model achieves 66.75% F0.5 and ranks 2nd on error detection and 4th on error correction in the shared task.
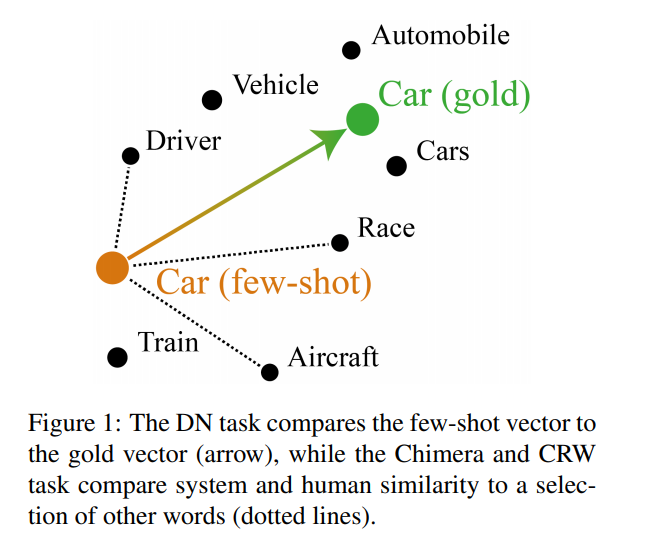
72. Bad Form: Comparing Context-Based and Form-Based Few-Shot Learning in Distributional Semantic Models
Jeroen Van Hautte, Guy Emerson, Marek Rei. Cambridge, Imperial, TechWolf. DeepLo 2019.
https://www.aclweb.org/anthology/D19-6104.pdf
Investigating embedding methods for rare words. Experiments demonstrate that existing baselines can achieve very competitive performance with some small modifications. Also showing the issues with common benchmarks when evaluating models that use word-form information and proposing 3 new variations of these tasks that address this.
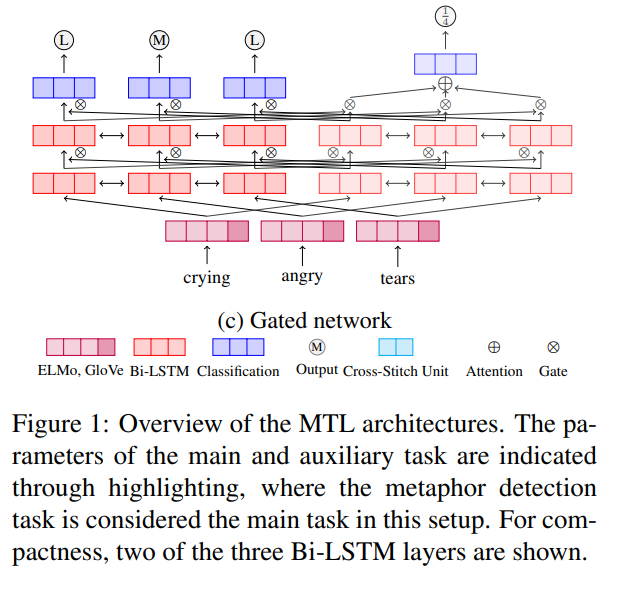
73. Modelling the interplay of metaphor and emotion through multitask learning
Verna Dankers, Marek Rei, Martha Lewis, Ekaterina Shutova. Amsterdam, Imperial, Cambridge. EMNLP 2019.
https://www.aclweb.org/anthology/D19-1227.pdf
Proposing a joint architecture for the detection of metaphorical language and emotion in text. Comparing hard parameter sharing, a cross-stitch network and a gated network where models predict either token-level labels or sentence-level scores. Evaluation on different metaphor and emotion datasets shows consistent improvements from multi-task learning, with the emotion
dimension of dominance contributing and benefiting most from metaphors.
74. Semi-Supervised Bootstrapping of Dialogue State Trackers for Task-Oriented Modelling
Bo-Hsiang Tseng, Marek Rei, Paweł Budzianowski, Richard Turner, Bill Byrne, Anna Korhonen. Cambridge, Imperial, PolyAI. EMNLP 2019.
https://www.aclweb.org/anthology/D19-1125.pdf
Methods for reducing the amount of required annotation in a task-oriented dialogue system. The first approach is based on pseudo-labelling, training on automatically labeled examples if the model confidence is high enough. The second approach perturbs the inputs and optimizes the model to predict the same belief states compared to the original input.
Presenting these summaries and links to the papers is a great value.
Thanks!
Thanks so much for these extremely helpful and clearly presented summaries.
Thank you so much for making this happen 🙂
thanks for summarizing all NLP related research papers at one place
thank you
Thank you so much for making this happen I really love this
Absolutely incredible work! Summarizing 74 ML and NLP research papers in one place is a huge time-saver and provides great clarity on current trends. A must-read resource for researchers, students, and enthusiasts alike.
“Super helpful! I often find blogs that are too generic, but your post was detailed and to the point. Thanks for making it clear.”a href=”https://azuretrainings.in/azure-data-engineer-training-in-hyderabad/”>Azure Data Engineer Training In Hyderabad
“Wow—this is such a treasure trove for anyone delving into ML and NLP! A crisp, no-frills summary of 74 papers from 2017–2019 in just about 30 minutes of reading? That’s brilliant. I especially appreciate how you keep the summaries blunt and focused on core contributions, making even complex topics like GPT-style pre-training, transformers, and unsupervised grammars feel approachable
aitopics.org
marekrei.com
.
Your commitment to breadth—and the way you capped it off by including your own papers at the end—adds a personal and scholarly touch
aitopics.org
. I also admire how you continuously help busy researchers by refining this format—your earlier version with 57 summaries was already incredibly useful.
This post is the kind of structured, high-value resource that makes keeping pace with the field manageable and even enjoyable. Thanks for doing the heavy lifting—I’ll definitely be sharing this with colleagues and consulting it often!”
Thanks to Admin of post for such great information. I like your blog post and subscribe your blog for all your future post.
Thanks to Admin of post for such great information.