The growth of interest in NLP technology, fuelled largely by investment in AI applications, has been accompanied by unprecedented expansion of the preeminent NLP conferences: ACL, NAACL and EMNLP in particular. Grzegorz Chrupała’s graph shows the rapid growth in submissions to each conference in recent years:
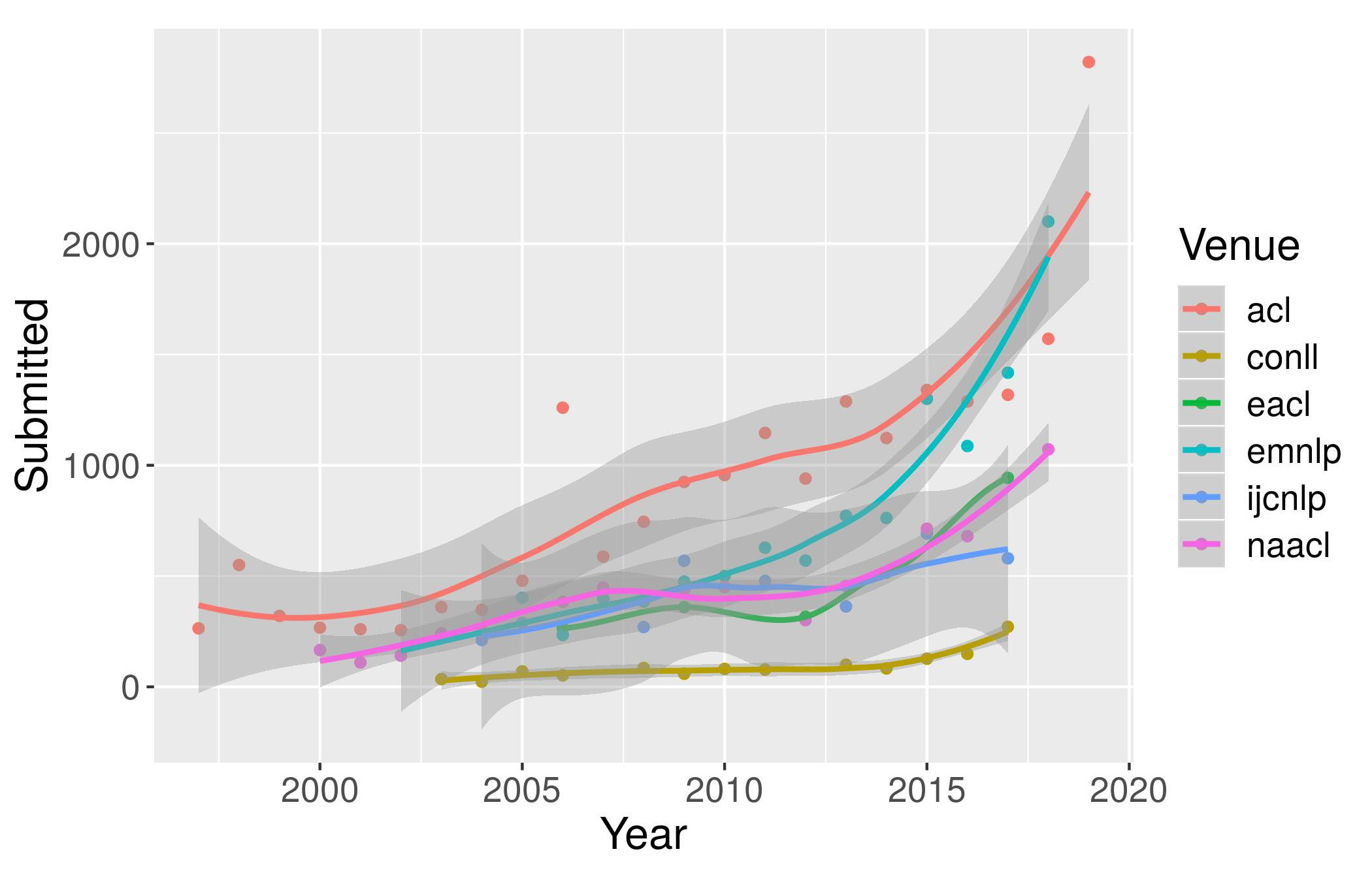
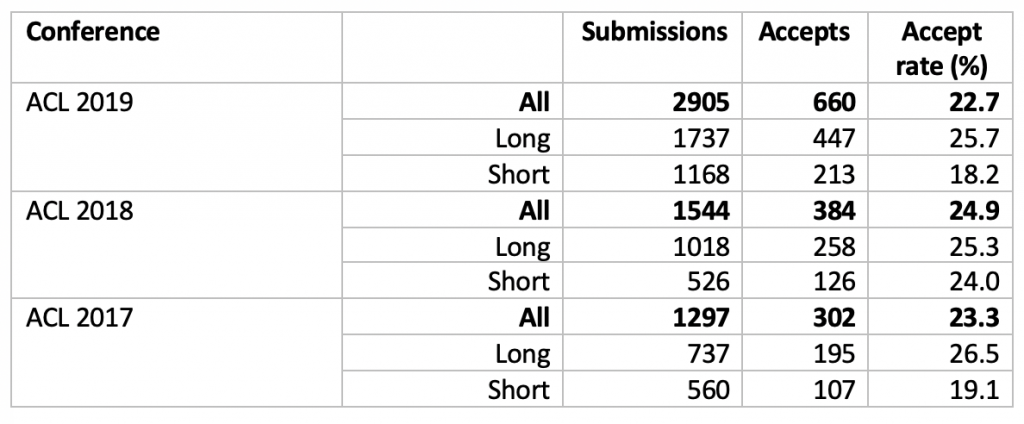
These trends can also be seen in the blog post by the ACL 2019 Chairs. Meanwhile, acceptance rates have tended to remain constant, meaning that the conferences have grown in line with submissions, e.g. from ACL 2019:
NLP has developed as a field narrowly focused on English, a point highlighted by the recent emergence (and need for) the #BenderRule. The ability of NLP models to deal with English is important, due to its status as an international language of politics, commerce and culture, and indeed with these tools we can handle, for instance, more than half the content on the internet. But with such a strong focus on English we miss cross-linguistic insights and lack coverage for the majority of languages in the world.
Many NLP researchers work cross-linguistically but still there is a core assumption that the L in NLP means written English, to such an extent that this fact is not always explicitly stated in papers and presentations. One way to continue to diversify the scope of the field would be increased diversity in geographic representation. This would give exposure to wider concerns than those of current participants in NLP research, and (optimistic assumption) lead to evaluation of new methods on a larger set of languages.
To take a measure of current geographic diversity in NLP, we extracted as many author affiliations as possible from fulltext papers in the ACL Anthology for 5 major conferences held in 2018: ACL, NAACL, EMNLP, COLING and CoNLL. We associated each author’s institution with a city and country, making some simple assumptions in the case of multinational organisations.1
In total from the N fulltext papers in the Anthology we extracted 2695 author affiliations. Within this set of affiliations we found 653 distinct institutions, in 325 different cities and 56 countries. These counts are impressive at first glance, and they point to a field with a healthy level of global interest. But recall that the United Nations recognises 193 member states, so the 2018 conferences achieved 29% coverage2 and inevitably there’s a bias towards North America, Asia, and Europe in terms of the regions represented by our list of countries. In particular there is a very stark lack of African representation in the dataset.
[table]
Region,N.author affiliations
North America, 1114
Asia, 826
Europe, 641
Middle East, 54
Oceania, 44
South America, 11
Africa, 5
[/table]
It is also a matter of concern that academic research in general lacks demographic diversity, with NLP being no exception. There are root causes here in terms of education systems, gender bias and global inequality, which are wider problems than NLP can solve alone. But doing everything possible to diversify the field would be a very positive move, especially given the link between AI, power and discrimination (see the ‘discriminating systems’ report by the AI Now Institute).
It may inform discussion if we report one other statistic we’ve been able to retrieve thanks to data sharing by Emily Bender & Leon Derczynski, the program chairs for COLING 2018. They provided us with anonymised submissions data from that conference, in which each submission was associated with a country thanks to the contact details provided by the corresponding author, as well as a final decision (accept, reject, ineligible, withdrawn, desk-reject). It became clear that acceptance rates were broadly equal, and gladly a bias against papers from certain regions was not apparent.
[table]
Country, Submissions, Acceptance Rate
Belgium, 5, 0.8
Netherlands, 17, 0.71
Hong Kong, 8, 0.63
Norway, 5, 0.6
Singapore, 14, 0.5
Israel, 8, 0.5
Italy, 13, 0.46
Switzerland, 7, 0.43
Canada, 24, 0.42
Denmark, 5, 0.4
France, 28, 0.39
Germany, 67, 0.39
UK, 36, 0.36
USA, 194, 0.35
Turkey, 6, 0.33
Japan, 59, 0.32
China, 297, 0.3
South Korea, 20, 0.25
Czech Republic, 9, 0.22
Australia, 9, 0.22
India, 76, 0.21
Taiwan, 11, 0.18
Russia, 7, 0.14
Sweden, 7, 0.14
Ireland, 7, 0.14
Brazil, 15, 0.13
Spain, 16, 0.13
Iran, 5, 0
[/table]
Of course we are not alone in hoping for increased diversity in NLP (conferences). We have noticed some positive developments in this regard especially in the past two years. For instance, COLING 2018 ran a writing mentoring programme expressly to help authors new to the field. The importance of guidance for those to whom (scientific) English is not a first language should not be underestimated. Nor should we assume that it is equally straightforward for all to learn English, with teaching quality and access to resources varying enormously by region (see John Clegg’s essay about sub-Saharan Africa, for example). There are also occasional calls for papers to be accepted in all languages. Perhaps there could be WMT shared tasks expressly working towards automatic paper translation into many languages.
NAACL has taken several positive steps including a diversity & inclusion committee for its 2019 conference, live captions by Microsoft, and the option to give remote presentations (good for those who cannot or do not like to travel, or cannot afford it). There’s also a NAACL emerging region fund to foster a larger and more cohesive comp-ling community in Latin America; meanwhile it’s been announced that the 2021 conference will be located in Mexico City, the first time it’s gone outside the US and Canada since the 1st conference in 2000.
2018 saw the launch of the Asia-Pacific Chapter of the Association for Computational Linguistics (AACL), which is organising its first conference next year (co-located with IJCNLP) in Suzhou, China. One good reason to take our major conferences to new countries is to equalise the barrier of obtaining visas to attend. Marina Dubova makes the point that potential participants from developing countries might only get visas for a minority of CogSci conference venues in recent times, as they have been almost exclusively held in the US, Canada and western Europe.
While there are positive signs in the Americas and Asia-Pacific regions, there is still a notable lack of NLP events and activity in Africa. ACL 2022 offers an opportunity to correct that with a call recently sent out to the members’ list for hosts in the Europe/Middle East/Africa region in July or August 2022. The interest and value in NLP (and AI more generally) in Africa is indicated by the creation of a Google AI office in Accra, Ghana, ICLR 2020 being held in Addis Adaba, Ethiopia, and a heavily over-subscribed master’s course run by the African Institute for Mathematical Sciences.
We set out to write this post with a focus on geographic diversity in NLP. In the meantime Strubell, Ganesh & McCallum’s paper on CO2 emission estimates from NLP model training made a telling impact at ACL 2019 and we realised that this issue is of wide interest in the field. We therefore sought to quantify CO2 emissions from conference attendance, by summing the air travel emissions for all locations in our database to the conference venue. Our calculations, made with some major caveats, suggest that delegate travel to the major NLP conferences in 2018 amounted to 2.1 million kg (4.6m lb) of CO2 emissions.4 This on top of the tonnes of CO2 put out training the models described at those conferences! There is of course much that is positive about in-person experience of international conferences, but each of us in the field has a responsibility to consider whether we should cut down on our travel. Some leading academics have already gone cold turkey, while others call for virtual attendance as a normal option. Put this together with a recent study finding no relationship between air travel and metrics of academic productivity and it’s clear that reducing long-distance conference travel should be something to consider.
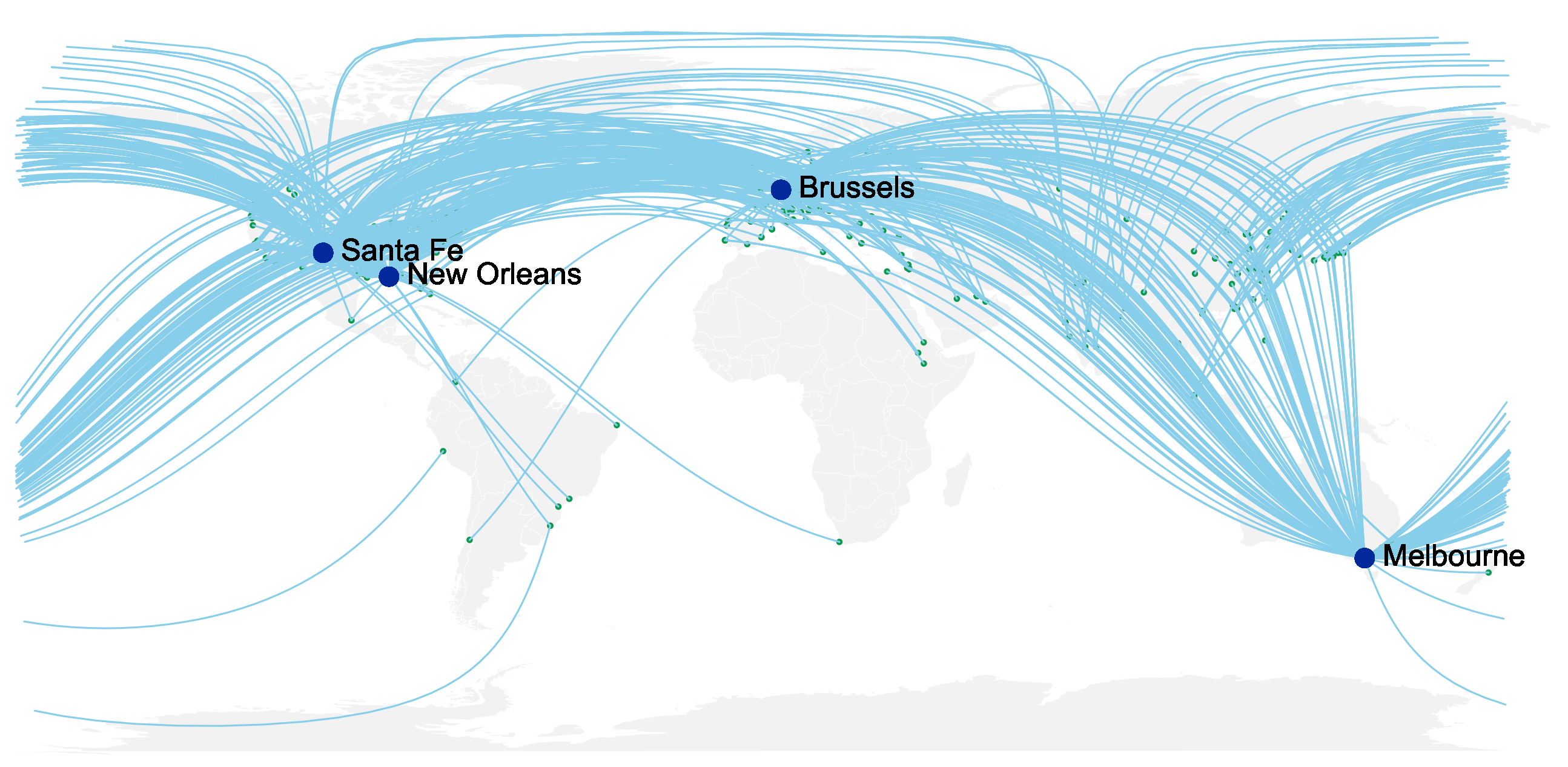
In summary, we wrote this blog post to highlight a lack of global representation at NLP conferences. This won’t be a surprising finding but we hope it is thought-provoking. How can the situation be improved? Of course, the root causes of the problem are much bigger issues than NLP can address alone. However, we’ve pointed to positive developments relating to NLP conferences, which we think could help improve the situation and should be widely adopted: writing mentoring programmes, diversity officers on conference committees, and remote presentation. In addition, holding more conferences in more regions (rather than allowing the existing few conferences to grow unchecked) is probably the better route to choose, both for diversity and environmental reasons. The first AACL conference in 2020 is very encouraging. We hope that an African bid might come through for ACL 2022, that EACL will take place more frequently, and that we’ll soon see inauguration of a South American (SAACL) and African (AfrACL) chapters of the ACL. How do we lobby for any of these things to happen? Please comment below!
This is a guest post by Andrew Caines, written in collaboration with Marek Rei. Andrew is a postdoctoral researcher at the University of Cambridge, working on automated language teaching and assessment.
The statistics in this post are based on the data crawled for the previous post on analysing ML/NLP publications in 2018.
We chose to use 2018 papers, as all the publications for 2019 are not available yet. Once these proceedings are published, there will be a new analysis coming for 2019 as well.
Footnotes
- In the case of multinational companies with an unspecified location we associated it with the location of its headquarters. If the author listed both an academic and industry affiliation we selected the academic one.
- This is a simplification of course, as the nationality of an author’s institution does not necessarily equal their own nationality, but at present we have no way to access that information, to the best of our knowledge, other than a questionnaire which not everyone would complete.
- Source: World Bank DataBank https://data.worldbank.org/indicator/sp.pop.totl
- Based on a total of 10.5m kilometres of air travel in the year and a per passenger kilometre multiplier of 200g which is based on a Boeing 747-400 flying at 80% seat occupancy (source: https://www.carbonindependent.org/22.html). Note the several important assumptions we’ve made for this estimate, and the impact of each one on the outcome: (1) That every city has an international airport: this means an overestimate of air miles, as many will travel by road or rail to the nearest international airport. On the other hand it is an underestimate of air miles because many will have to take a connecting flight via another airport, either because of routing or financial restrictions. (2) Similarly, at the other end, an assumption that every conference venue has an international airport: true for Melbourne, Brussels, New Orleans, not so for Santa Fe which has only a regional airport. Making the assumption of flight to Santa Fe is a fair one, rather than guessing which of the nearest international hubs, Dallas, Las Vegas or Denver (or otherwise) each person flew to. (3) That every attendee travels by air to the conference rather than land or sea-based modes of transport (note that those less than 100 miles from the venue are assumed not to have flown). (4) That every paper author attends the conference: no doubt an over-estimate. (5) That there are no conference attendees without a paper to present: no doubt an under-estimate.
Thank you for the fantastic blog and for collating all those statistics. Speaking from the context of the African NLP community, I see some great things happening:
1. The Deep Learning Indaba has been strengthening machine learning across the continent. The event has been super successful. You can read about it here: https://onezero.medium.com/africa-is-building-an-a-i-industry-that-doesnt-look-like-silicon-valley-72198eba706d or here: http://deeplearningindaba.com
And check out the NLP sessions at the Indaba championed by Sebastian Ruder and Herman Kamper here: https://sites.google.com/view/nlpdlindaba
2. Africa now has publications present at NeurIPS and ICML and ICLR. To our knowledge, last year was the first time work from African institution got into the main conference at NeurIPS
3. Due to the Indaba, other movements have risen up. This year we hosted our first African NLP UnConference: https://sites.google.com/view/sautiyetu-nlp/home and, we’ve gone and started https://masakhane.io – a movement of young African NLP researchers looking to change the colour of Africa on that map you have above by collecting & discovering data and building models together.
Things I think the world can do to assist African participating in the global conversation:
– “We hope that an African bid might come through for ACL 2022”. We wish to do this, but we will likely need support from more experienced ACL hosts. The reason an event like ICLR can happen in Addis is due to the support of established African researchers who work abroad such as Timnit Gebru and Shakir Mohammed – as well as massive lobbying from Yoshio Bengio himself. The support of the ACL board could make this work and I know the Deep Learning Indaba has the experience of running events on the continent and would offer their support.
– Offer to assist/mentor others in organising workshops that support the work African languages (researchers that publish in a workshop one year, will likely feel brave enough and supported enough to submit to the main conference next year)
Hi Jade,
Just seen your comments. Thank you! 🙂
We chatted already on Twitter about the Indaba and Masakhane, but just want to say thanks again for pointing us to those. Good to hear about the unconference too.
About the final 2 points: yes totally hoping there’ll be some mentoring to make these things happen. I just noticed that the deadline is November so this is probably all too late for ACL 2022 — but for the next available call, it’d be good if people interested in hosting can talk with people experienced in hosting. Let us know if you know of anyone in the former category and we can try to put them in touch with people in the latter category.
As for a workshop, I notice that LREC (Marseille 2020) just extended their workshop proposal deadline until 31st October. Would this be of any interest? Or it’s a case of next year’s *ACL workshop call (in early Autumn I think), which allows a longer run at it..
Andrew
Pingback:ML and NLP Publications in 2019 - Marek Rei
Thanks for the article. Much thanks again. Cool!.
Hi there,
I am new to this field as a public health researcher based in Cape Town, South Africa. Are there other conferences or networking opportunities for researchers from Africa in this space?
I look forward to hearing from you.