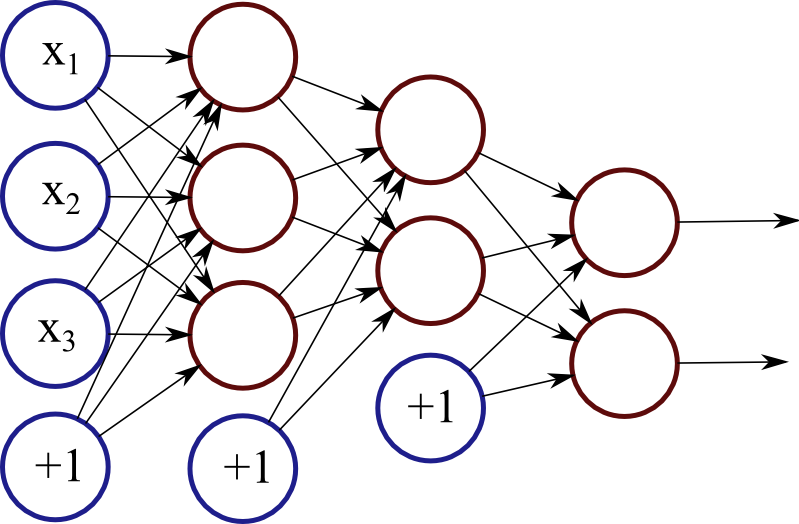
Neural networks have a range of interesting applications, and here I will discuss on one them: recursive neural networks and the detection of political ideology. This post is a summary and analysis of a recent publication by Mohit Iyyer, Peter Anns, Jordan Boyd-Graber and Philip Resnik: “Political Ideology Detection Using Recursive Neural Networks“.
The Task
Given a sentence, we want the model to detect the political ideology expressed in that sentence. In this research, the authors deal with US politics, so the possible options are liberal (democrats) or conservative (republicans). As a practical application we might consider a system that processes a large amount of news articles or public speeches to detect and measure explicit or hidden political bias of the authors.

A traditional approach to this problem is a simple bag-of-words model, where each word is treated as a separate feature, but this ignores any syntactic structure and even word order. As shown below, political ideology can be compositionally complicated – while certain sections of the sentence are locally conservative, the way they are used in context makes the overall sentence liberal.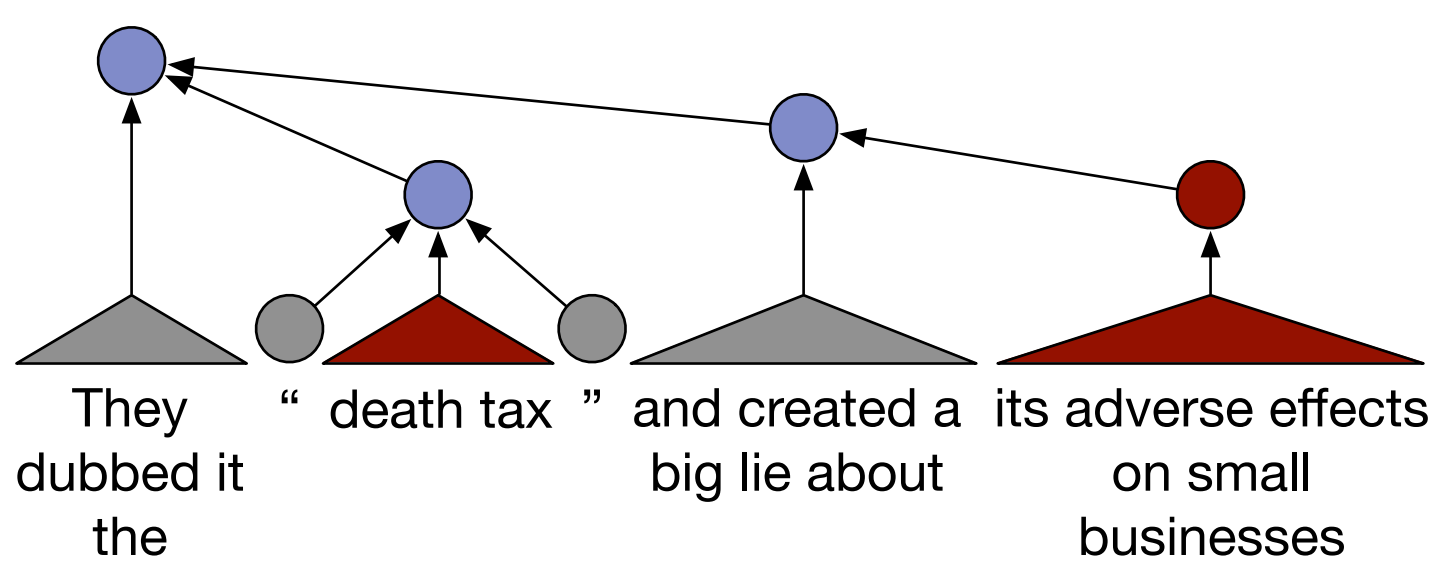
Figure 1: Sample sentence from Iyyer et al. (2014). Blue nodes are liberal, red nodes are conservative, grey nodes are neutral.