It has been a very productive year for NLP and ML research. Both areas continued to grow, with conferences reaching record numbers of publications. In this post I will break these numbers down a bit more, by individual authors and organisations. The statistics cover the following venues: ACL, EMNLP, NAACL, EACL, COLING, TACL, CL, CoNLL, *Sem+SemEval, NIPS, ICML, ICLR. Compared to last year, I’ve now included ICLR which has grown very rapidly in the last two years and become a highly competitive conference.
The analysis is done automatically, by crawling publication information from the conference websites and ACL Anthology. Author names are usually listed in the proceedings and easily extractable, however the organisation names are more tricky and need to be extracted straight from the PDFs. I’ve created a number of rules to map together alternative names and misspellings, but let me know if you notice any errors.
Venues
First, let’s look at different publication venues between 2012-2017. NIPS is clearly heading off the charts, with 677 publications this year. Most other venues are also growing rapidly, with 2017 being the biggest year ever for ICML, ICLR, EMNLP, EACL and CoNLL. In contrast, TACL and CL seem to be keeping a constant number of publications per year. NAACL and COLING were notably missing from 2017, but we can look forward to both of them in 2018.
Authors
The most prolific author of 2017 is Iryna Gurevych (TU Darmstadt) with 18 papers. Lawrence Carin (Duke University) has 16 publications, with an impressive 10 papers at NIPS. Following them closely are Yue Zhang (Singapore), Yoshua Bengio (Montreal), and Hinrich Schütze (Munich).
Looking at cumulative statistics from 2012-2017, Chris Dyer (DeepMind) is at the top with an impressive lead, followed by Iryna Gurevych (TU Darmstadt) and Noah A. Smith (Washington). Lawrence Carin (Duke), Zoubin Ghahramani (Cambridge) and Pradeep K. Ravikumar (CMU) are publishing mainly in the general ML venues, while the others are balanced between NLP and ML.
Separating the publications by year shows that Chris Dyer has scaled down the publication count to a more manageable level this year, and Iryna Gurevych is developing an impressive upward trajectory.
First Authors
Now let’s look at first authors, as these are usually the people implementing the code and running the experiments. Ivan Vulić (Cambridge), Ryan Cotterell (Johns Hopkins) and Zeyuan Allen-Zhu (Microsoft Research) have all produced an impressive 6 first-author publications in 2017. They are followed by Henning Wachsmuth (Weimar), Tsendsuren Munkhdalai (Microsoft Maluuba), Jiwei Li (Stanford) and Simon S. Du (CMU).
Organisations
Looking at the publishing patterns of different organisations in 2017, Carnegie Mellon is leading the charge with 126 publications, followed by Google, Microsoft and Stanford. Universities that publish proportionally more in the general ML area compared to NLP include MIT, Columbia, Oxford, Harvard, Toronto, Princeton and Zürich. In contrast, universities and organisations that focus more on the NLP venues include Edinburgh, IBM, Peking, Washington, Johns Hopkins, Pennsylvania, CAS, Darmstadt, and Qatar.
Looking at the whole period between 2012-2017, CMU is again in the lead with Microsoft, Google and Stanford close behind.
Looking at the time series, it seems CMU, Stanford, MIT and Berkeley are on the upward trajectory in terms of publications. In contrast, the industry leaders Google, Microsoft and IBM have slightly scaled back their publication numbers.
Topic Clustering
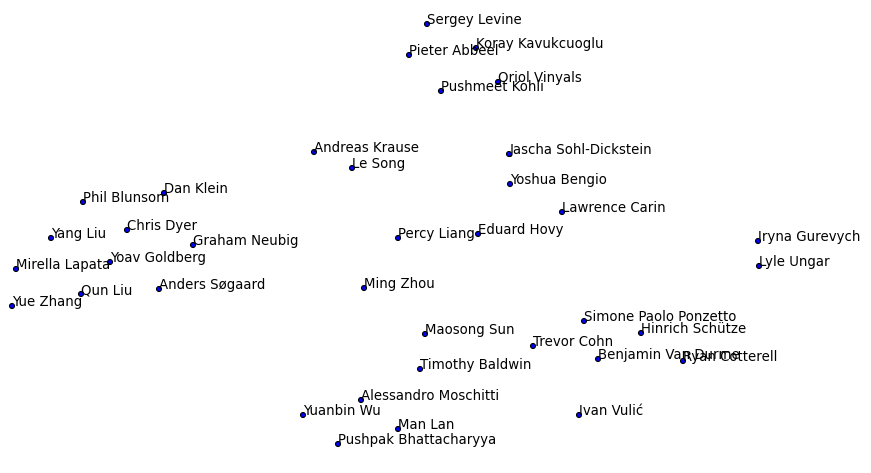
Finally, I did LDA on all the paper texts from authors that had 9 or more publications and visualised the results using tsne. In the middle is the topic of general machine learning, neural networks and adversarial learning. The top cluster covers reinforcement learning and different learning policies. The cluster on the left contains NLP applications, language modelling, parsing and machine translation. The cluster at the bottom covers information modelling and feature spaces.
That’s it for 2017. If you notice errors, let me know and I will continue updating this post.
Looking forward to all the exciting research coming in 2018!
In the last few years and with the advent of deep learning, the NLP world has become filled to the brim with useless bandwagon publications, bogus claims, and tons of name dropping. The results from many of these supposedly stellar papers are not reproducible, and are not useful in practice because either the authors don’t release their code or report only on cherry-picked datasets that don’t reflect the messiness of the real world data.
What I see is a strange form of craving to churn out more papers with little to no real contribution to the field. We should take a step back and ask whether there is enough fundamental research in NLP/CL. Maybe I am too pessimistic, but I fail to see that.
It’s true that these statistics only measure quantity and not quality. I tried to approximate the latter by only including the top conferences in the field, but quality remains a very difficult metric to measure.
I do agree that there are a lot of unnecessary papers in the field, although I’m not sure if their ratio has actually increased or it’s just the result of more people working in that area.
Great analysis, thanks for sharing it!
One question on the selection of venues: If the conferences of both the American (NAACL) and European (EACL) chapters of ACL are included, why not Asia Pacific (IJCNLP)? Leaving out that conference seeems to bias the analysis towards certain regions, especially the author statistics.
For this analysis I chose the main conferences that I personally follow. To be honest, I don’t know much about IJCNLP. I’m happy to consider it in the future, but there are loads of other conferences that could potentially be included as well. Also, according to the ACL Anthology, it’s not an ACL event and is listed in the “Other” section instead.
Although when I first saw the topic Ml-Nlp publications, I was thinking distribution of publications among subfields of Ml, Nlp , still found it to be an interesting read.
Pingback:57 Summaries of Machine Learning and NLP Research - Marek Rei
Nice analysis! For the first author, will the co-first author been encountered? There should be a footnote in the first page which shows the equal contribution status.
Is this information accurate ? For example, for Percy Liang it shows 0 NIPS’17 papers, but I can see 3 on his page: https://cs.stanford.edu/~pliang/papers/
It’s as accurate as I could make it with automatic matching. It seems he is credited as “Percy S. Liang” in the NIPS proceedings, as opposed to “Percy Liang” in the ACL proceedings.
I’ll add a rule to fix this in the next version, but unfortunately I can’t see a reliable way of discovering these exceptions automatically.