Staying on top of recent work is an important part of being a good researcher, but this can be quite difficult. Thousands of new papers are published every year at the main ML and NLP conferences, not to mention all the specialised workshops and everything that shows up on ArXiv. Going through all of them, even just to find the papers that you want to read in more depth, can be very time-consuming.
In this post, I have summarised 50 papers. After going through a paper, if I had the chance, I would write down a few notes and summarise the work in a couple of sentences. These are not meant as reviews – I’m not commenting on whether I think the paper is good or not. But I do try to present the crux of the paper as bluntly as possible, without unnecessary sales tactics. Hopefully this can give you the general idea of 50 papers, in roughly 20 minutes of reading time.
The papers are not selected or ordered based on any criteria. It is not a list of the best papers I have read, more like a random sample. The only filter that I applied was to exclude papers older than 2016, as the goal is to give an overview of the more recent work.
I set out to summarise 50 papers. Once I was done, I thought this would be a sensible place to summarise my own work as well. So at the end of the list you will also find brief summaries of the papers I published in 2017.
Let’s get started.
1. A Thorough Examination of the CNN/Daily Mail Reading Comprehension Task
Danqi Chen, Jason Bolton, Christopher D. Manning. Stanford. ACL 2016.
https://arxiv.org/pdf/1606.02858.pdf
Hermann et al (2015) created a dataset for testing reading comprehension by extracting summarised bullet points from CNN and Daily Mail. All the entities in the text are anonymised and the task is to place correct entities into empty slots based on the news article.
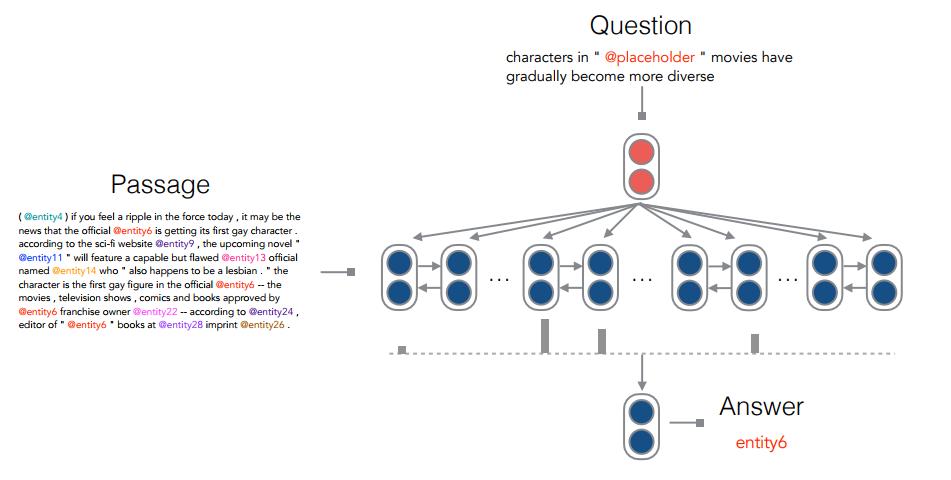
This paper has hand-reviewed 100 samples from the dataset and concludes that around 25% of the questions are difficult or impossible to answer even for a human, mostly due to the anonymisation process. They present a simple classifier that achieves unexpectedly good results, and a neural network based on attention that beats all previous results by quite a margin.
2. Word Translation Without Parallel Data
Alexis Conneau, Guillaume Lample, Marc’Aurelio Ranzato, Ludovic Denoyer, Hervé Jégou. Facebook, Le Mans, Sorbonne. ArXiv 2017.
https://arxiv.org/pdf/1710.04087.pdf
Inducing word translations using only monolingual corpora for two languages. Separate embeddings are trained for each language and a mapping is learned though an adversarial objective, along with an orthogonality constraint on the most frequent words. A strategy for an unsupervised stopping criterion is also proposed.
3. A Nested Attention Neural Hybrid Model for Grammatical Error Correction
Jianshu Ji, Qinlong Wang, Kristina Toutanova, Yongen Gong, Steven Truong, Jianfeng Gao. ACL 2017.
http://aclweb.org/anthology/P/P17/P17-1070.pdf
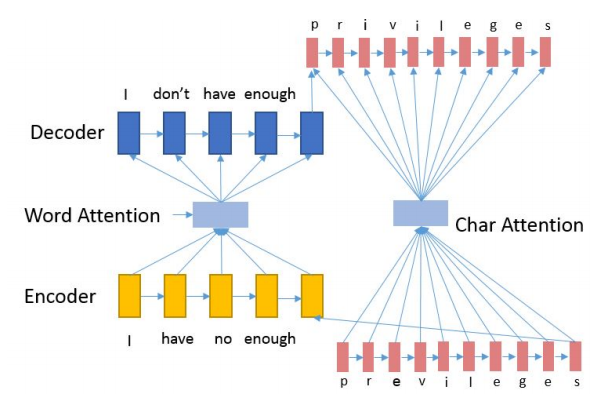
Proposing character-based extensions to a neural MT system for grammatical error correction. OOV words are represented in the encoder and decoder using character-based RNNs. They evaluate on the CoNLL-14 dataset, integrate probabilities from a large language model, and achieve good results.
4. On-line Active Reward Learning for Policy Optimisation in Spoken Dialogue Systems
Pei-Hao Su, Milica Gasic, Nikola Mrksic, Lina Rojas-Barahona, Stefan Ultes, David Vandyke, Tsung-Hsien Wen, Steve Young. Cambridge. ACL 2016.
http://aclweb.org/anthology/P/P16/P16-1230.pdf
The goal is to improve the training process for a spoken dialogue system, more specifically a telephone-based system providing restaurant information for the Cambridge (UK) area. They train a supervised system which tries to predict the success on the current dialogue – if the model is certain about the outcome, the predicted label is used for training the dialogue system; if the model is uncertain, the user is asked to provide a label. Essentially it reduces the amount of annotation that is required, by choosing which examples should be annotated through active learning.
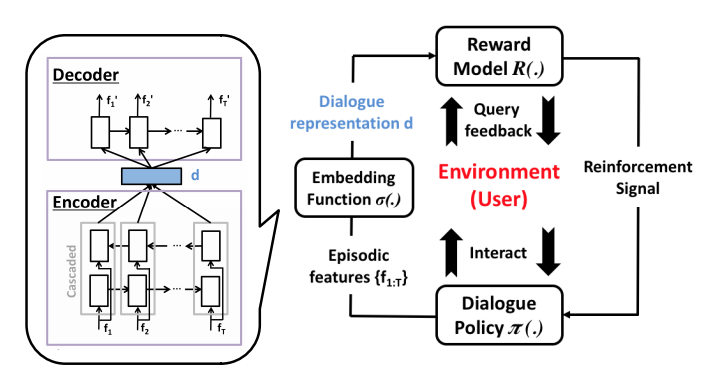
The dialogue is mapped to a vector representation using a bidirectional LSTM trained like an autoencoder, and a Gaussian Process is used for modelling dialogue success.
5. Vision and Feature Norms: Improving automatic feature norm learning through cross-modal maps
Luana Bulat, Douwe Kiela, Stephen Clark. Cambridge. NAACL 2016.
http://aclweb.org/anthology/N/N16/N16-1071.pdf
The task is to predict feature norms – object properties, for example is_yellow and is_edible for the word banana. They experiment with adding in image recognition features, in addition to using distributional word vectors.
An input word is used to retrieve 10 images from Google, these are passed through an ImageNet classifier to get feature vectors, and then averaged to get a vector representation for that word. A supervised model (partial least-squares regression) is then trained to predict vectors of feature norms based on the input vectors (image-based, distributional, or a combination). Including the image information helps quite a bit, especially for detecting properties like colour and shape.

6. Adversarial examples in the physical world
Alexey Kurakin, Ian J. Goodfellow, Samy Bengio. Google, OpenAI. ArXiv.
https://arxiv.org/abs/1607.02533
Adversarial examples are datapoints that are designed to fool a classifier. For example, we can take an image that is classified correctly using a neural network, then backprop through the model to find which changes we need to make in order for it to be classified as something else. And these changes can be quite small, such that a human would hardly notice a difference.

In this paper, they show that much of this property holds even when the images are fed into the classifier from the real world – after being photographed with a cell phone camera. While the accuracy goes from 85.3% to 36.3% when adversarial modifications are applied on the source images, the performance still drops from 79.8% to 36.4% when the images are photographed. They also propose two modifications to the process of generating adversarial images – making it into a more gradual iterative process, and optimising for a specific adversarial class.
7. Extracting token-level signals of syntactic processing from fMRI – with an application to POS induction
Joachim Bingel, Maria Barrett, Anders Søgaard. Copenhagen. ACL 2016.
http://aclweb.org/anthology/P/P16/P16-1071.pdf
They incorporate fMRI features into POS tagging, under the assumption that reading semantically/functionally different words will activate the brain in different ways. For this they use a dataset of fMRI recordings, where the subjects were reading a chapter of Harry Potter. The main issue is that fMRI has very low temporal resolution – there is only one fMRI reading per 4 tokens, and in general it takes around 4-14 seconds for something to show up in fMRI. Nevertheless, they construct token-level vectors by using a Gaussian weighted average, integrate them into an unsupervised POS tagger, and show that it is able to improve performance.
8. Joint Extraction of Events and Entities within a Document Context
Bishan Yang, Tom Mitchell. Carnegie Mellon. NAACL 2016.
http://aclweb.org/anthology/N/N16/N16-1033.pdf
They propose a joint model for 1) identifying event keywords in a text, 2) identifying entities, and 3) identifying the connections between these events and entities. They also do this across different sentences, jointly for the whole text.

The entity detection part is done with a CRF; the structure of an event is learned with a probabilistic graphical model; information is integrated from surrounding sentences using a Stanford coreference system; and these are all tied together across the whole document using Integer Linear Programming.
9. Candidate re-ranking for SMT-based grammatical error correction
Zheng Yuan, Ted Briscoe, Mariano Felice. Cambridge. BEA Workshop 2016.
https://www.aclweb.org/anthology/W/W16/W16-0530.pdf
They improve an existing error correction system by re-ranking its predictions. The basic approach uses machine translation to perform error correction on learner texts – the incorrect text is essentially translated into correct text. Here, they include a ranking SVM to score and reorder the n-best lists from the translation model.
The reranking features include various internal scores from the translation model, the rank in the original ordering, language model probabilities trained on large corpora, language model scores based on only the n-best list, word-level translation probabilities, and sentence length features. They show improvement on two error correction datasets.

10. Variational Neural Machine Translation
Biao Zhang, Deyi Xiong, Jinsong Su, Hong Duan, Min Zhang. Soochow University, Xiamen University. ArXiv.
https://arxiv.org/abs/1605.07869
They start with the neural machine translation model using alignment, by Bahdanau et al. (2014), and add an extra variational component.
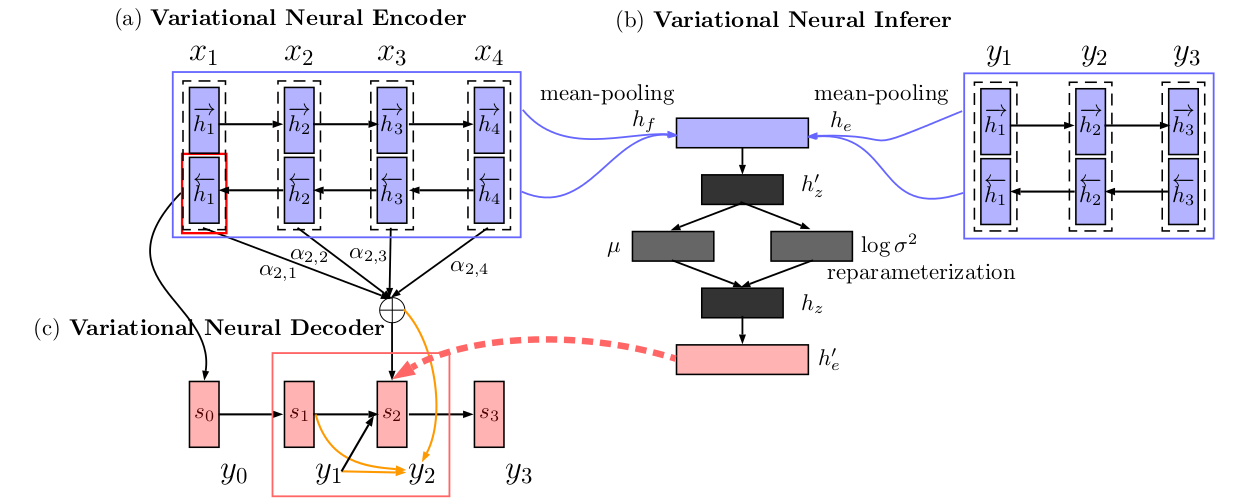
The authors use two neural variational components to model a distribution over latent variables z that captures the semantics of a sentence being translated. First, they model the posterior probability of z, conditioned on both input and output. Then they also model the prior of z, conditioned only on the input. During training, these two distributions are optimised to be similar using Kullback-Leibler distance, and during testing the prior is used. They report improvements on Chinese-English and English-German translation, compared to using the original encoder-decoder NMT framework.
11. Numerically Grounded Language Models for Semantic Error Correction
Georgios P. Spithourakis, Isabelle Augenstein, Sebastian Riedel. UCL. EMNLP 2016.
https://arxiv.org/abs/1608.04147
They create an LSTM neural language model that 1) has better handling of numerical values, and 2) is conditioned on a knowledge base.
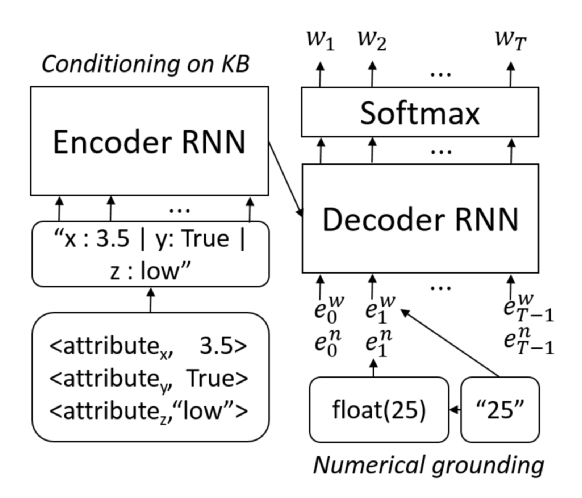
First the the numerical value each token is given as an additional signal to the network at each time step. While we normally represent token “25” as a normal word embedding, we now also have an extra feature with numerical value float(25). Second, they condition the language model on text in a knowledge base. All the information in the KB is converted to a string, passed through an LSTM and then used to condition the main LM.
They evaluate on a dataset of 16,003 clinical records which come paired with small KB tuples of 20 possible attributes. The numerical grounding helps quite a bit, and the best results are obtained when the KB conditioning is also added.
12. Black Holes and White Rabbits : Metaphor Identification with Visual Features
Ekaterina Shutova, Douwe Kiela, Jean Maillard. Cambridge. NAACL 2016.
https://www.aclweb.org/anthology/N/N16/N16-1020.pdf
They build a system for detecting metaphors (“blind alley”, “honest meal”, etc) from literal word pairs.
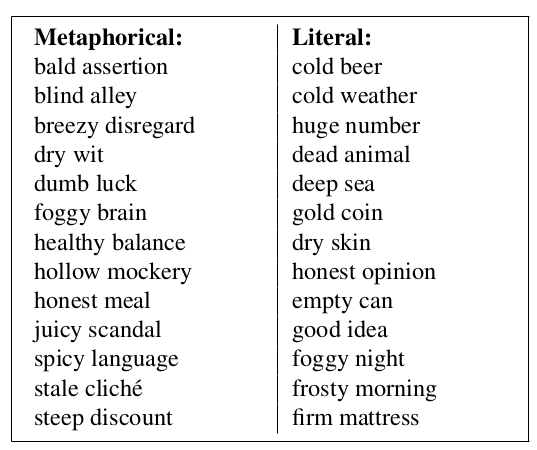
The basic system uses word embedding similarity – cosine between the word embeddings. Then they explore variations using phrase embeddings, cos(phrase-word2, word2), which is similar to the operations with word regularities by Mikolov.
Finally, they create vector representations for words and phrases using visual information. The words are used as queries in Google Image Search, and the returned images are passed through an image detection network in order to obtain vector representations. The best final system performs the task separately using linguistic and visual vectors, and then combines the resulting scores.
13. Counter-fitting Word Vectors to Linguistic Constraints
Nikola Mrkšić, Diarmuid Ó Séaghdha, Blaise Thomson, Milica Gašić, Lina Rojas-Barahona, Pei-Hao Su, David Vandyke, Tsung-Hsien Wen, Steve Young. Cambridge, Apple. NAACL 2016.
http://www.aclweb.org/anthology/N16-1018
They describe a method for augmenting existing word embeddings with knowledge of semantic constraints. The idea is similar to retrofitting by Faruqui et al. (2015), but using additional constraints and a different optimisation function.
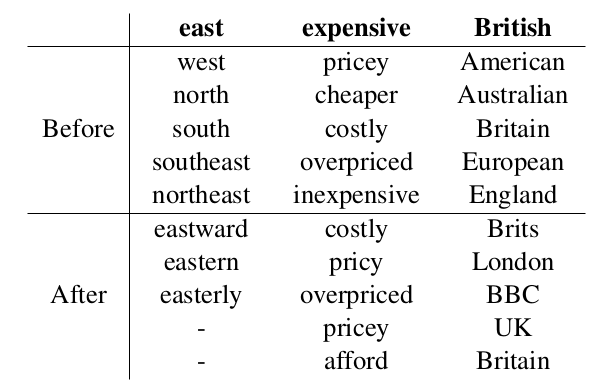
Existing word vectors are further optimised to 1) have high similarity for known synonyms, 2) have low similarity for known antonyms, and 3) have high similarity to words that were highly similar in the original space. They evaluate on SimLex-999, showing state-of-the-art performance. Also, they use the method to improve a dialogue tracking system.
14. Bidirectional RNN for Medical Event Detection in Electronic Health Records
Abhyuday N. Jagannatha, Hong Yu. University of Massachusetts. NAACL 2016.
https://www.aclweb.org/anthology/N/N16/N16-1056.pdf
The authors have a dataset of 780 electronic health records and they use it to detect various medical events such as adverse drug events, drug dosage, etc. The task is done by assigning a label to each word in the document.
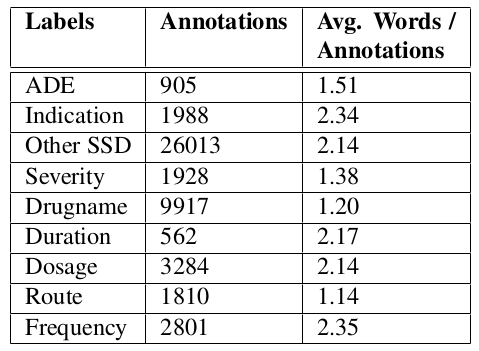
They look at CRFs, LSTMs and GRUs. Both LSTMs and GRUs outperform the CRF, but the best performance is achieved by a GRU trained on whole documents.
15. Symmetric Patterns and Coordinations: Fast and Enhanced Representations of Verbs and Adjectives
Roy Schwartz, Roi Reichart, Ari Rappoport. The Hebrew Universit, IIT. NAACL 2016.
http://www.aclweb.org/anthology/N16-1060
They train word2vec skip-gram embeddings using coordinations as context. They use 11 manual patterns to extract coordinations (eg “X and Y”, “either X or Y”, etc). From “boats or planes”, “boats” will be a context of “planes” and “planes” will be a context of “boats”.
They evaluate on SimLex-999 and find that this performs badly on nouns. However, it beats normal skip-gram and dependency-based skip-gram on verbs and adjectives.
16. Comparing Data Sources and Architectures for Deep Visual Representation Learning in Semantics
Douwe Kiela, Anita L. Verő, Stephen Clark. Cambridge. EMNLP 2016.
https://aclweb.org/anthology/D/D16/D16-1043.pdf
The authors compare different image recognition models and image data sources for multimodal word representation learning.
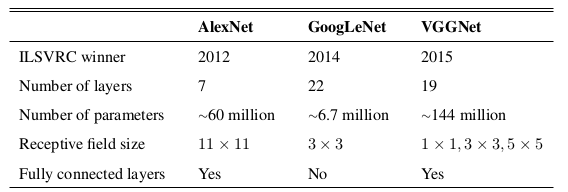
Experiments are performed on SimLex-999 (similarity) and MEN (relatedness). The performance of different models (AlexNet, GoogLeNet, VGGNet) is found to be quite similar, with VGGNet performing slightly better at the cost of requiring more computation. Using search engines for image sources gives good coverage; ImageNet performs quite well with VGGNet; ESP Game dataset gave the lowest performance. Combining visual and linguistic vectors was found to be beneficial on both English and Italian.
17. Named Entity Recognition for Novel Types by Transfer Learning
Lizhen Qu, Gabriela Ferraro, Liyuan Zhou, Weiwei Hou, Timothy Baldwin. Melbourne. EMNLP 2016.
http://aclweb.org/anthology/D16-1087
The authors tackle the problem of domain adaptation for NER, where the label set of the target domain is different from the source domain.
They first train a CRF model on the source domain. Next, they train a LR classifier to predict labels in the target domain, based on predicted label scores from the model. Finally, the weights from the classifier are used to initialise another CRF model, which is then fine-tuned on the target domain data.
18. Hybrid computing using a neural network with dynamic external memory
Alex Graves, Greg Wayne, Malcolm Reynolds et al. DeepMind. Nature.
http://www.nature.com/nature/journal/v538/n7626/full/nature20101.html
The DeepMind guys present an extension to the Neural Turing Machine architecture.
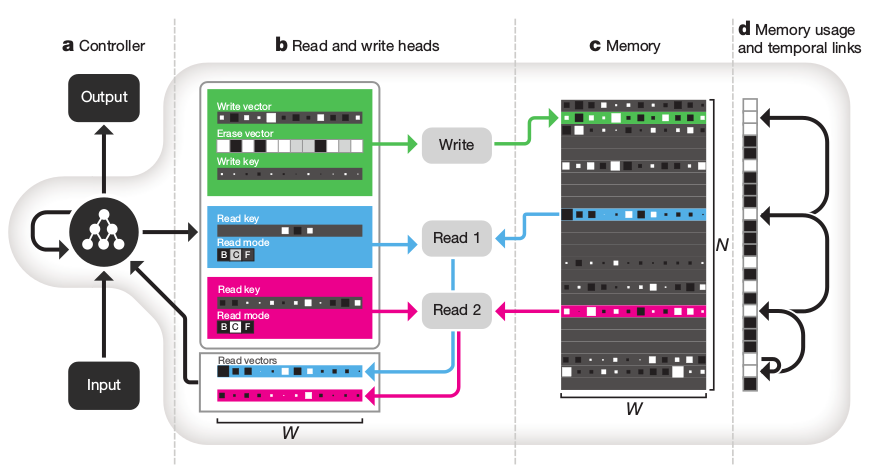
They call it a Differentiable Neural Computer (DNC) and it uses 1) an attention mechanism to access information in a matrix that acts as a memory, 2) an attention mechanism to save information to that memory, and 3) a transition matrix that stores information about the order in which rows in the memory are modified, in order to better handle sequential information. They test on the bAbI question answering dataset, a graph inference task, and on solving a puzzle of arranging blocks.
19. A Neural Approach to Automated Essay Scoring
Kaveh Taghipour, Hwee Tou Ng. Singapore. EMNLP 2016.
https://aclweb.org/anthology/D/D16/D16-1193.pdf
The authors construct a neural network for automated essay scoring.
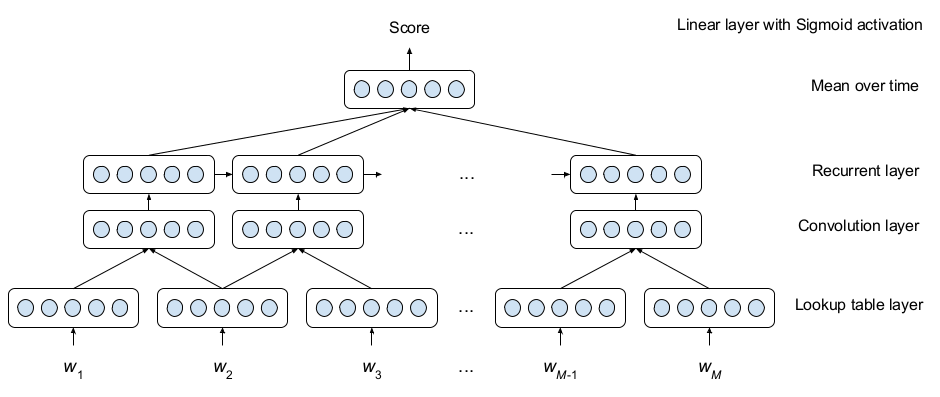
Convolution window of 3 is passed over the text, which is used as input to an LSTM. The output of the LSTM is averaged over all timesteps and then a single value in the range of [0,1] is predicted as a scaled-down score for the essay. They evaluate by measuring quadratic weighted Kappa on the Kaggle essay scoring dataset.
20. Globally Coherent Text Generation with Neural Checklist Models
Chloe Kiddon, Luke Zettlemoyer, Yejin Choi. Washington. EMNLP 2016.
https://aclweb.org/anthology/D/D16/D16-1032.pdf
They describe a neural model for text generation, which keeps track of a checklist of items that need to be mentioned in the text.
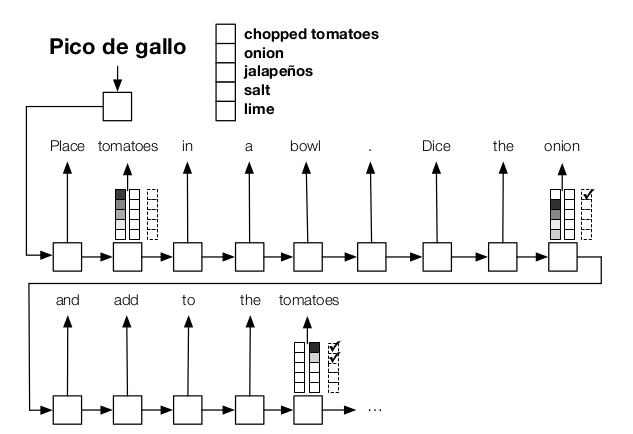
The basic system is an encoder-decoder GRU model for text generation. On top of that, the model uses attention over items that need to be mentioned and items that have already been mentioned, both of which are encoded as vectors. An additional cost objective encourages the checklist to be filled by the end of the text. Evaluation is performed on recipe and dialogue generation.
21. Automatic Features for Essay Scoring – An Empirical Study
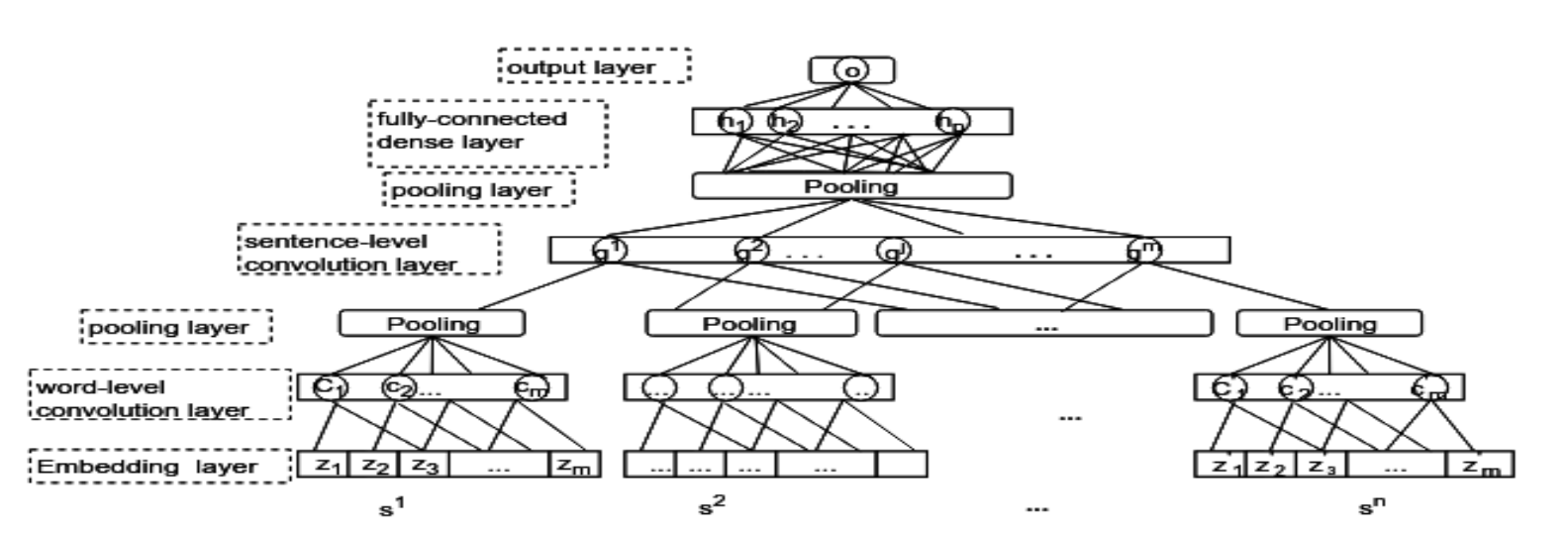
Fei Dong, Yue Zhang. Singapore. EMNLP 2016.
https://www.aclweb.org/anthology/D/D16/D16-1115.pdf
The authors investigate convolutional networks for essay scoring. They use a two-level convolution – first over words and then over sentences. Evaluation is performed on the Kaggle ASAP dataset, training separate models on individual topics, and also reporting some cross-topic results.
22. Learning Deep Structure-Preserving Image-Text Embeddings
Liwei Wang, Yin Li, Svetlana Lazebnik. University of Illinois, Georgia Tech. CVPR 2016.
http://www.cv-foundation.org/…CVPR_2016_paper.pdf
The authors present a neural model that maps images and sentences into the same space, in order to perform cross-modal retrieval – find images based on a sentence or find sentences based on an image.
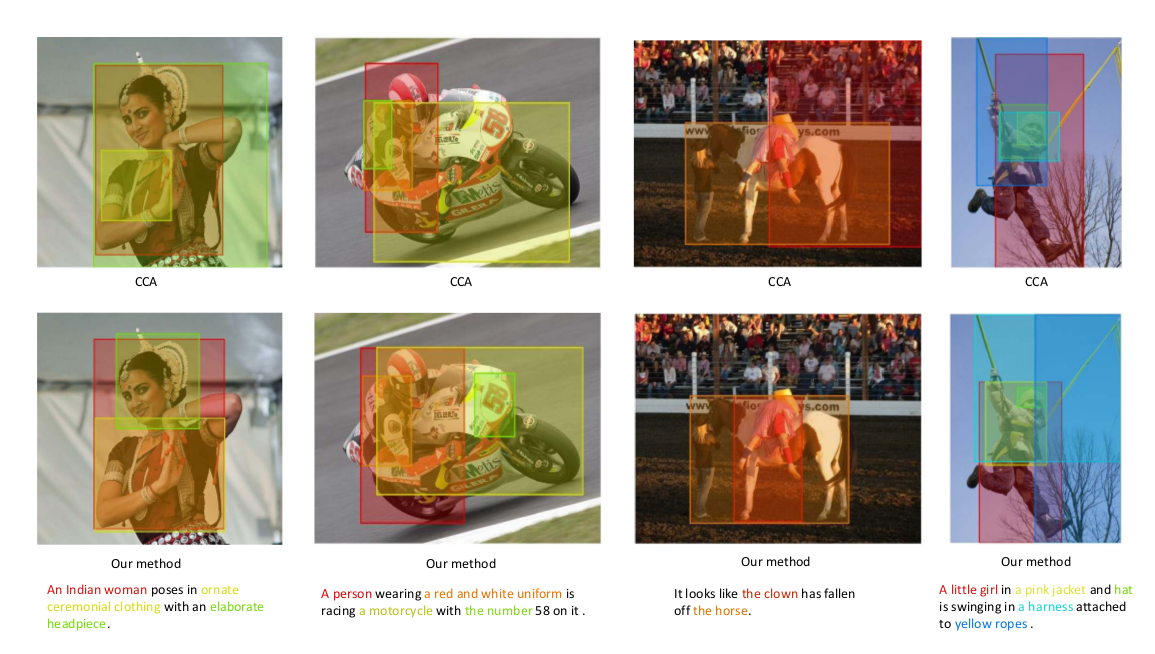
The image vectors come from a pre-trained VGG image detection network. The sentence vectors are constructed using Fisher vectors, but they also explore simpler options, such as mean word2vec vectors and tfidf. Both are then mapped through nonlinearities and normalised, and Euclidean distance is used to measure vector similarity. They also investigate the task of mapping noun phrases from the image caption to specific areas of the image.
23. Understanding deep learning requires rethinking generalization
Chiyuan Zhang, Samy Bengio, Moritz Hardt, Benjamin Recht, Oriol Vinyals. Google Brain, DeepMind. ICLR 2017.
https://arxiv.org/pdf/1611.03530.pdf
The authors investigate the generalisation properties of several well-known image recognition networks.
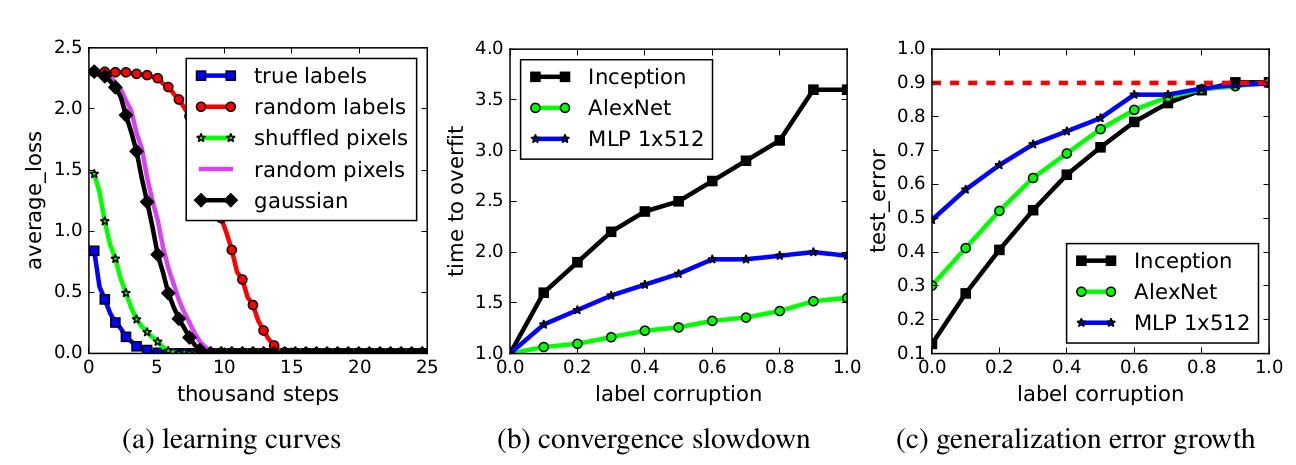
They show that these networks are able to overfit to the training set with 100% accuracy even if the labels on the images are random, or if the pixels are randomly generated. Regularisation, such as weight decay and dropout, doesn’t stop overfitting as much as expected, still resulting in ~90% accuracy on random training data. They then argue that these models likely make use of massive memorization, in combination with learning low-complexity patterns, in order to perform well on these tasks.
24. Reinforcement Learning with Unsupervised Auxiliary Tasks
Max Jaderberg, Volodymyr Mnih, Wojciech Marian Czarnecki Tom Schaul, Joel Z Leibo, David Silver & Koray Kavukcuoglu. DeepMind. ICLR 2017.
https://arxiv.org/abs/1611.05397
They describe a version of reinforcement learning where the system also learns to solve some auxiliary tasks, which helps with the main objective.
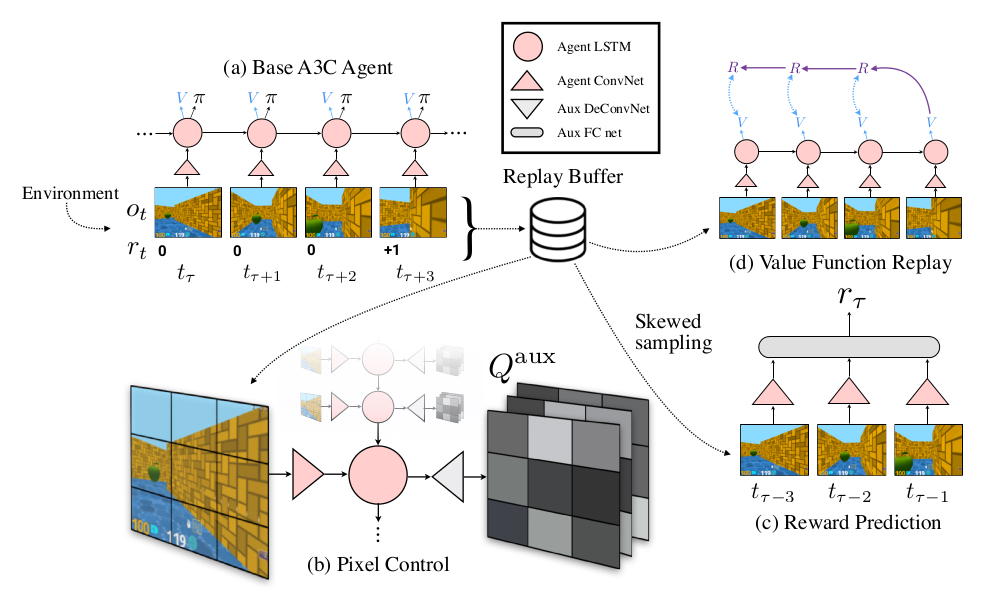
In addition to normal Q-learning, which predicts the downstream reward, they have the system learning 1) a separate policy for maximally changing the pixels on the screen, 2) maximally activating units in a hidden layer, and 3) predicting the reward at the next step, using biased sampling. They show that this improves learning speed and performance on Atari games and Labyrinth (a Quake-like 3D game).
25. Modelling metaphor with attribute-based semantics
Luana Bulat, Stephen Clark, Ekaterina Shutova. Cambridge. EACL 2017.
http://aclweb.org/anthology/E/E17/E17-2084.pdf
They propose using attribute-based vectors for detecting metaphorical word pairs.
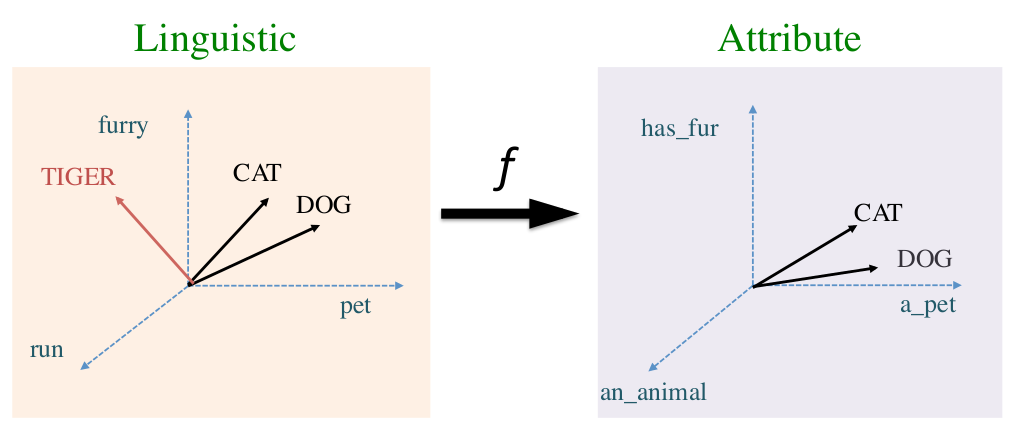
Traditional embeddings (word2vec and count-based) are mapped to attribute vectors, using a supervised system trained on McRae norms. These vectors for a word pair are then given as input to an SVM classifier and trained to detect metaphorical (black humour) vs literal (black dress) word pairs. They show that using the attribute vectors gives higher F score over using the original vector space.
26. Enriching Word Vectors with Subword Information
Piotr Bojanowski, Edouard Grave, Armand Joulin, Tomas Mikolov. Facebook. ArXiv 2016.
https://arxiv.org/abs/1607.04606
They extend skip-grams for word embeddings to use character n-grams. Each word is represented as a bag of character n-grams, 3-6 characters long, plus the word itself. Each of these has their own embedding which gets optimised to predict the surrounding context words using skip-gram optimisation. They evaluate on word similarity and analogy tasks, in different languages, and show improvement on most benchmarks.
27. Learning to Compose Words into Sentences with Reinforcement Learning
Dani Yogatama, Phil Blunsom, Chris Dyer, Edward Grefenstette, Wang Ling. DeepMind. ICLR 2017.
https://arxiv.org/abs/1611.09100
The aim is to have the system discover a method for parsing that would benefit a downstream task.
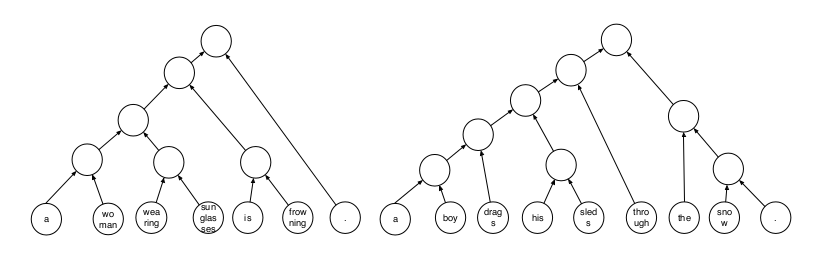
They construct a neural shift-reduce parser – as it’s moving through the sentence, it can either shift the word to the stack or reduce two words on top of the stack by combining them. A Tree-LSTM is used for composing the nodes recursively. The whole system is trained using reinforcement learning, based on an objective function of the downstream task. The model learns parse rules that are beneficial for that specific task, either without any prior knowledge of parsing or by initially training it to act as a regular parser.
28. Identifying beneficial task relations for multi-task learning in deep neural networks
Joachim Bingel, Anders Søgaard. Copenhagen. EACL 2017.
http://www.aclweb.org/anthology/E17-2026
The authors investigate the benefit of different task combinations when performing multi-task learning.
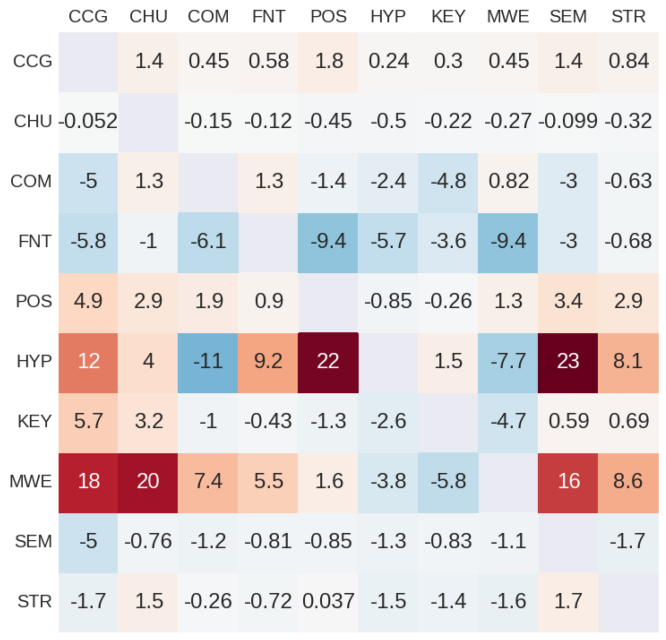
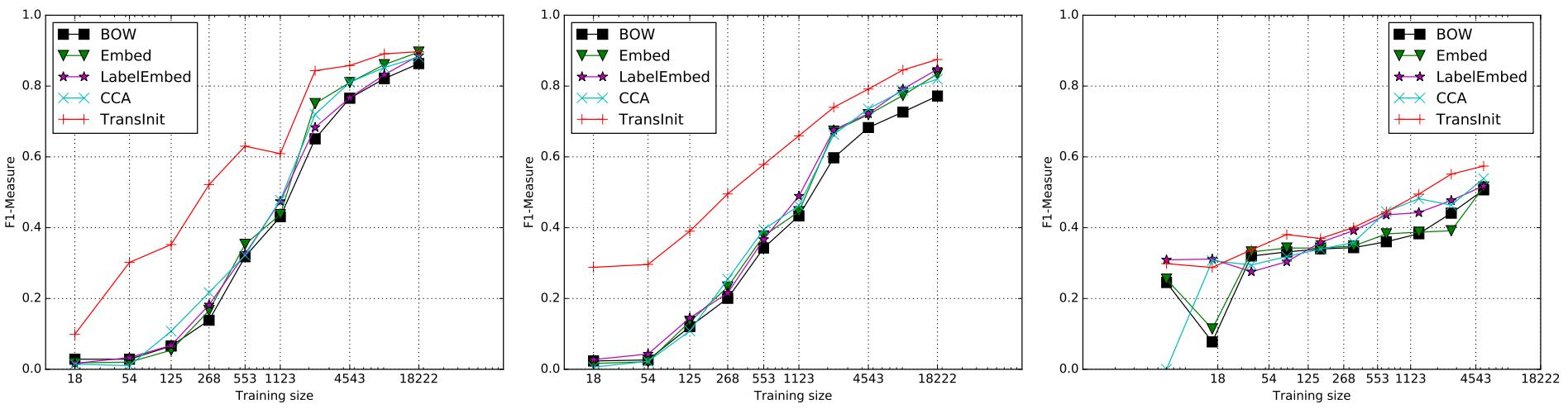
They experiment with all possible pairs of 10 sequence labeling datasets, switching between the datasets during training. They find that multi-task learning helps more when the main task quickly plateaus while the auxiliary task does not, likely helping the model out of local minima.
There does not seem to be any auxiliary task that would help on all main tasks, but chunking and semantic tagging seem to perform best.
29. Literal and Metaphorical Senses in Compositional Distributional Semantic Models
E. Darío Gutiérrez, Ekaterina Shutova, Tyler Marghetis, Benjamin K. Bergen. UCSD, Cambridge, Bloomington. ACL 2016.
http://www.aclweb.org/anthology/P16-1018
The paper investigates compositional semantic models specialised for metaphors.
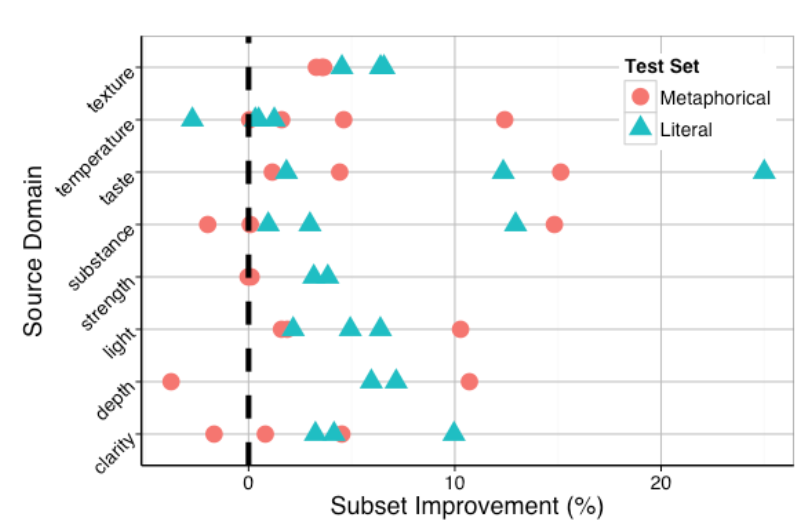
They construct a dataset of 8592 adjective-noun phrases, covering 23 different adjectives, annotated for being metaphorical or literal. They then train compositional models to predict the phrase vector based on the noun vector, as a linear combination with an adjective-specific weight matrix. They show that it’s better to learn separate adjective matrices for literal and metaphorical uses of each adjective, even though the amount of training data is smaller.
30. Data Noising as Smoothing in Neural Network Language Models
Ziang Xie, Sida I. Wang, Jiwei Li, Daniel Levy, Aiming Nie, Daniel Jurafsky, Andrew Y. Ng. Stanford. ICLR 2017.
https://arxiv.org/abs/1703.02573
The paper investigates better noising techniques for RNN language models.

A noising technique from previous work would be to randomly replace words in the context or replace them with a blank token. Here they investigate ways of choosing better which words to replace and choosing the replacements from a better distribution, inspired by methods in n-gram smoothing. They show improvement on language modeling (PTB and text8) and machine translation (English-German).
31. Neural Belief Tracker: Data-Driven Dialogue State Tracking
Nikola Mrkšić, Diarmuid Ó Séaghdha, Tsung-Hsien Wen, Blaise Thomson, Steve Young. Cambridge, Apple. ACL 2017.
http://aclweb.org/anthology/P/P17/P17-1163.pdf
They propose neural models for dialogue state tracking, making a binary decision for each possible slot-value pair, based on the latest context from the user and the system. The context utterances and the slot-value option are encoded into vectors, either by summing word representations or using a convnet. These vectors are then further combined to produce a binary output. The systems are evaluated on two dialogue datasets and show improvement over baselines that use hand-constructed lexicons.
![]()
32. Neural Architectures for Fine-grained Entity Type Classification
Sonse Shimaoka, Pontus Stenetorp, Kentaro Inui, Sebastian Riedel. Tohoku, UCL. EACL 2017.
https://www.aclweb.org/anthology/E17-1119
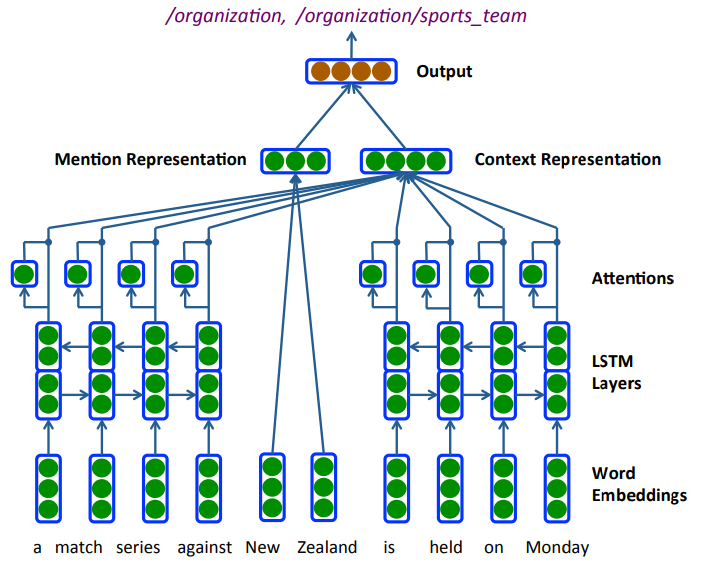
They propose a neural architecture for assigning fine-grained labels to detected entity types. The model combines bidirectional LSTMs, attention over the context sequence, hand-engineered features, and the label hierarchy. They evaluate on Figer and OntoNotes datasets, showing improvements from each of the extensions.
33. Recurrent Additive Networks
Kenton Lee, Omer Levy, Luke Zettlemoyer. Washington, Allen Institute. ArXiv 2017.
https://arxiv.org/abs/1705.07393
The authors propose a simplified version of LSTMs. Some non-linearities and weighted components are removed, in order to arrive at the recurrent additive network (RAN). The model is evaluated on 3 language modeling datasets: PTB, the billion word benchmark, and character-level Text8.
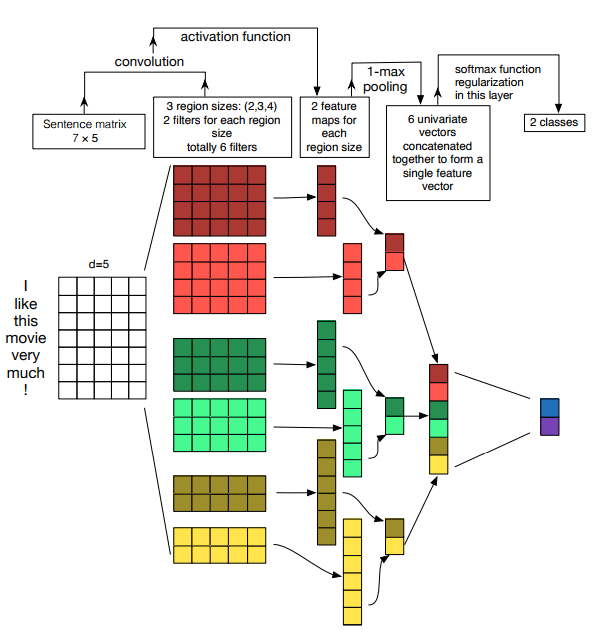
34. A Sensitivity Analysis of (and Practitioners’ Guide to) Convolutional Neural Networks for Sentence Classification
Ye Zhang, Byron Wallace. UT Austin. IJCNLP 2017.
https://www.aclweb.org/anthology/I/I17/I17-1026.pdf
The authors perform a hyperparameter search for a single-layer CNN on 9 different sentence classification datasets.
They find that the optimal embedding initialisation, filter size and number of feature maps depends on the dataset and should be chosen through a search; ReLU and tanh are the best activation functions; 1-max pooling is the pooling method; dropout may help when the number of feature maps gets large.
35. On Using Monolingual Corpora in Neural Machine Translation
Caglar Gulcehre, Orhan Firat, Kelvin Xu, Kyunghyun Cho, Loic Barrault, Huei-Chi Lin, Fethi Bougares, Holger Schwenk, Yoshua Bengio. Montreal, METech, Maine. Computer Speech and Language 2016.
https://arxiv.org/abs/1503.03535
The authors extend a seq2seq model for MT with a language model. They first pre-train a seq2seq model and a neural language model, then train a separate feedforward component that takes the hidden states from both and combines them together to make a prediction. They compare to simply combining the output probabilities from both models (shallow fusion) and show improvement on different MT datasets.

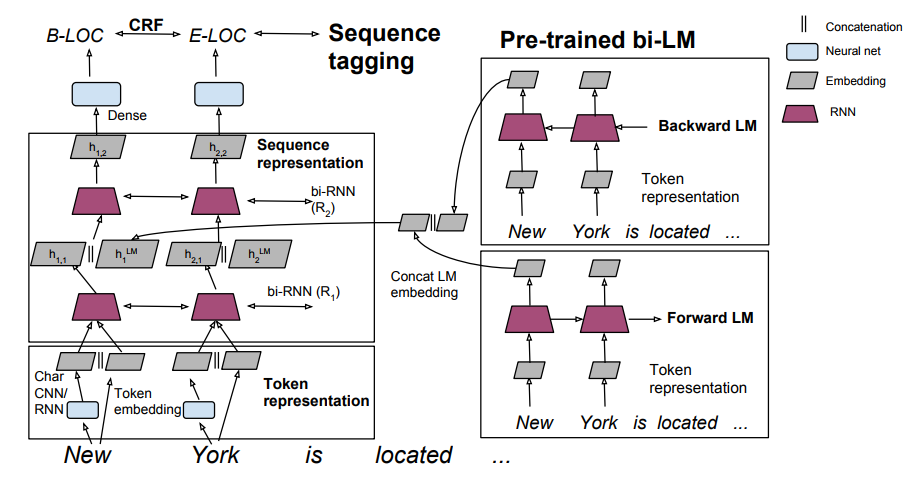
36. Semi-supervised sequence tagging with bidirectional language models
Matthew E. Peters, Waleed Ammar, Chandra Bhagavatula, Russell Power. Allen Institute. ACL 2017.
http://aclweb.org/anthology/P/P17/P17-1161.pdf
The paper proposes integrating a pre-trained language model into a sequence labeling model. The baseline model for sequence labeling is a two-layer LSTM/GRU. They concatenate the hidden states from pre-trained language models onto the output of the first LSTM layer. This provides an improvement on NER and chunking tasks.
37. Weakly Supervised Part-of-speech Tagging Using Eye-tracking Data
Maria Barrett, Joachim Bingel, Frank Keller, Anders Søgaard. Copenhagen. ACL 2016.
https://www.aclweb.org/anthology/P/P16/P16-2094.pdf
The paper explores the usefulness of eye tracking for the task of POS tagging. The assumption is that readers skip quickly over closed class words, and fixate longer on rare on ambiguous words.
The experiments are performed on unsupervised POS tagging – a second-order HMM uses constraints on possible tags for each word (based on a dictionary), but no explicit annotated data is required. They show that including the eye tracking features improves performance by quite a bit. Surprisingly, it seems to be better to average eye tracking features over all training tokens of the same type, as opposed to using using the data for each individual token, which means eye tracking is only used during the training stage.
38. Massive Exploration of Neural Machine Translation Architectures
Denny Britz, Anna Goldie, Minh-Thang Luong, Quoc Le. Google Brain. EMNLP 2017.
http://aclweb.org/anthology/D17-1151
Investigates different parameter choices for encoder-decoder NMT models. They find that LSTM is better than GRU, 2 bidirectional layers is enough, additive attention is the best, and a well-tuned beam search is important. They achieve good results on the WMT15 English->German task and release the code.

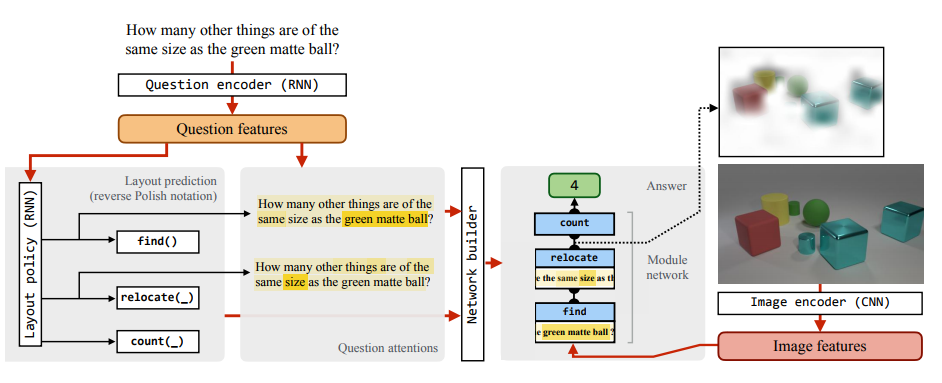
39. Learning to Reason: End-to-End Module Networks for Visual Question Answering
Ronghang Hu, Jacob Andreas, Marcus Rohrbach, Trevor Darrell, Kate Saenko. Berkeley, Facebook, Boston. ICCV 2017.
https://arxiv.org/pdf/1704.05526.pdf
A modular neural architecture for visual question answering. A seq2seq component predicts the sequence of neural modules (eg find() and compare()) based on the textual question, which are then dynamically combined and trained end-to-end. Achieves good results on three separate benchmarks that focus on reasoning about the image.
40. Automatic Annotation and Evaluation of Error Types for Grammatical Error Correction
Christopher Bryant, Mariano Felice, Ted Briscoe. Cambridge. ACL 2017.
http://aclweb.org/anthology/P/P17/P17-1074.pdf
A toolkit for automatically annotating error correction data with error types. It takes original and corrected sentences as input, aligns them to infer error spans, and uses rules to assign error types. They use the tool to perform fine-grained evaluation of CoNLL-14 shared task participants.
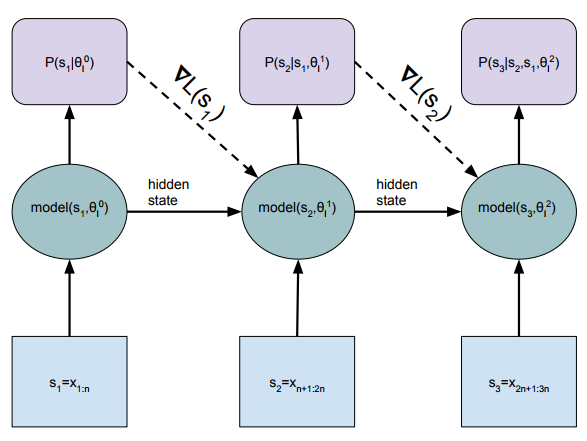
41. Dynamic Evaluation of Neural Sequence Models
Ben Krause, Emmanuel Kahembwe, Iain Murray, Steve Renals. Edinburgh. ArXiv 2017.
https://arxiv.org/abs/1709.07432
Updating the parameters in a LSTM language model based on the observed sequence during testing. A slice of text is first processed and then used for a gradient descent update step. A regularisation term is also proposed which draws the parameters back towards the original model.
42. Unsupervised Machine Translation Using Monolingual Corpora Only
Guillaume Lample, Ludovic Denoyer, Marc’Aurelio Ranzato. Facebook, Sorbonne. ArXiv 2017.
https://arxiv.org/abs/1711.00043
The model learns to translate using a seq2seq model, an autoencoder objective, and an adversarial objective for language identification.
The system is trained to correct noisy versions of its own output and iteratively improves performance.
Does not require parallel corpora, but relies on a separate method for inducing a parallel dictionary that bootstraps the translation.
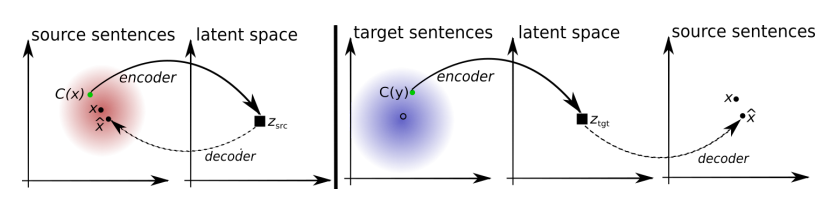
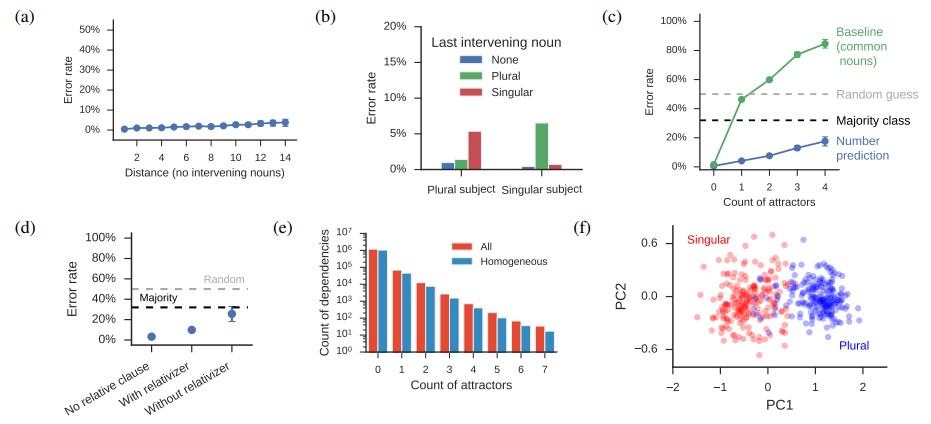
43. Assessing the Ability of LSTMs to Learn Syntax-Sensitive Dependencies
Tal Linzen, Emmanuel Dupoux, Yoav Goldberg. ENS, Bar Ilan. TACL 2017.
http://aclweb.org/anthology/Q/Q16/Q16-1037.pdf
Investigation of how well LSTMs capture long-distance dependencies. The task is to predict verb agreement (singular or plural) when the subject noun is separated by different numbers of distractors. They find that an LSTM trained explicitly for this task manages to handle even most of the difficult cases, but a regular language model is more prone to being misled by the distractors.
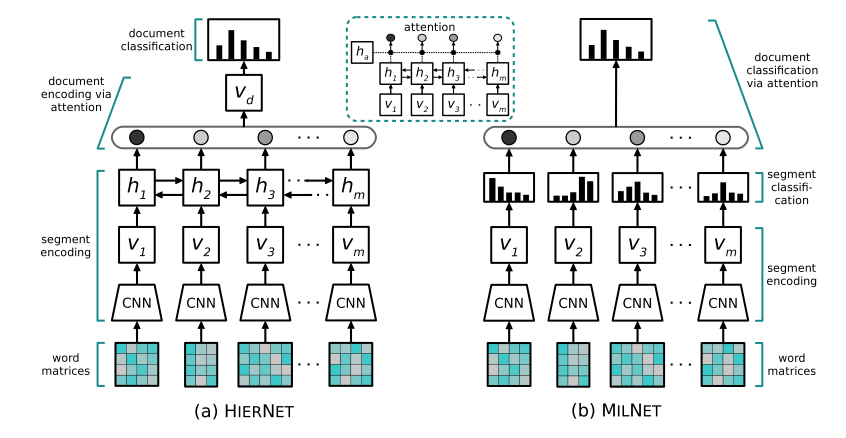
44. Multiple Instance Learning Networks for Fine-Grained Sentiment Analysis
Stefanos Angelidis, Mirella Lapata. Edinburgh. ArXiv 2017.
https://arxiv.org/pdf/1711.09645.pdf
A model for document sentiment classification which can also return sentence-level sentiment predictions. They construct sentence-level representations using a convnet, use this to predict a sentence-level probability distribution over possible sentiment labels, and then combine these over all sentences either with a fixed weight vector or using an attention mechanism. They release a new dataset of 200 documents annotated on the level of sentences and discourse units.
45. Learning how to Active Learn: A Deep Reinforcement Learning Approach
Meng Fang, Yuan Li, Trevor Cohn. Melbourne. EMNLP 2017.
http://aclweb.org/anthology/D/D17/D17-1063.pdf
Active learning (choosing which examples to annotate for training) is proposed as a reinforcement learning problem. The Q-learning network predicts for each sentence whether it should be annotated, and is trained based on the performance improvement from the main task. Evaluation is done on NER, with experiments on transferring the trained Q-learning function to other languages.
46. On the State of the Art of Evaluation in Neural Language Models
Gábor Melis, Chris Dyer, Phil Blunsom. Deepmind, Oxford. ArXiv 2017.
https://arxiv.org/pdf/1707.05589.pdf
Comparison of three recurrent architectures for language modelling: LSTMs, Recurrent Highway Networks and the NAS architecture. Each model goes through a substantial hyperparameter search, under the constraint that the total number of parameters is kept constant. They conclude that basic LSTMs still outperform other architectures and achieve state-of-the-art perplexities on two datasets.
47. Dynamic Routing Between Capsules
Sara Sabour, Nicholas Frosst, Geoffrey E Hinton. Google Brain. NIPS 2017.
https://arxiv.org/pdf/1710.09829.pdf
An attention-based architecture for combining information from different convolutional layers. The attention values are calculated using an iterative process, making use of a custom squashing function. The evaluations on MNIST show robustness to affine transformations.
48. Multilingual Part-of-Speech Tagging with Bidirectional Long Short-Term Memory Models and Auxiliary Loss
Barbara Plank, Anders Søgaard, Yoav Goldberg. Groningen, Copenhagen, Bar-Ilan. ACL 2016.
http://aclweb.org/anthology/P/P16/P16-2067.pdf
Doing POS tagging using a bidirectional LSTM with word- and character-based embeddings. They add an extra component to the loss function – predicting a frequency class for each word, together with their POS tag. Results show that overall performance remains similar, but there’s an improvement in tagging accuracy for low-frequency words.
49. Emergent Translation in Multi-Agent Communication
Jason Lee, Kyunghyun Cho, Jason Weston, Douwe Kiela. Facebook. ArXiv 2017.
https://arxiv.org/pdf/1710.06922.pdf
Learning to translate using two monolingual image captioning datasets and pivoting through images. The model encodes an image and generates a caption in language A, this is then encoded into the same space as language B and the representation is optimised to be similar to the correct image. The model is trained end-to-end using Gumbel-softmax.
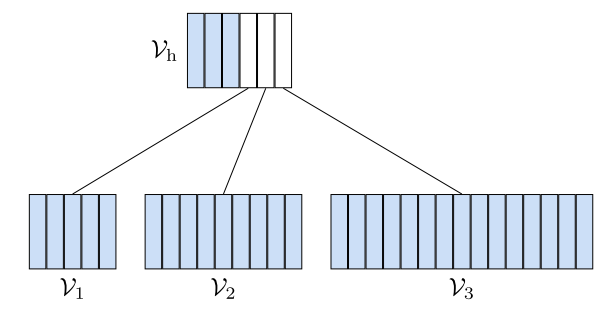
50. Efficient softmax approximation for GPUs
Edouard Grave, Armand Joulin, Moustapha Cissé, David Grangier, Hervé Jégou. Facebook. ICML 2017.
https://arxiv.org/pdf/1609.04309.pdf
Modification of the 2-level hierarchical softmax for better efficiency. An equation of computational complexity is used to find the optimal number of words in each class. In addition, the most common words are considered on the same level as other classes.
51. Semi-supervised Multitask Learning for Sequence Labeling
Marek Rei. Cambridge. ACL 2017.
http://aclweb.org/anthology/P/P17/P17-1194.pdf
Incorporating an unsupervised language modeling objective to help train a bidirectional LSTM for sequence labeling. At the same time as training the tagger, the forward-facing LSTM is optimised to predict the next word and the backward-facing LSTM is optimised to predict the previous word. The model learns a better composition function and improves performance on NER, error detection, chunking and POS-tagging, without using additional data.
52. Grasping the Finer Point: A Supervised Similarity Network for Metaphor Detection
Marek Rei, Luana Bulat, Douwe Kiela, Ekaterina Shutova. Cambridge, Facebook. EMNLP 2017.
http://aclweb.org/anthology/D/D17/D17-1162.pdf
A specialised architecture for detecting metaphorical phrases. Uses a gating mechanism to condition one word based on the other, a neural version of weighted cosine similarity to make a prediction and hinge loss to optimise the model. Achieves high results on detecting metaphorical adjective-noun, verb-object and verb-subject phrases.
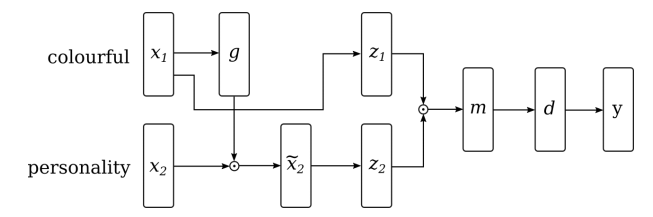
53. Neural Sequence-Labelling Models for Grammatical Error Correction
Helen Yannakoudakis, Marek Rei, Øistein E. Andersen, Zheng Yuan. Cambridge. EMNLP 2017.
http://aclweb.org/anthology/D/D17/D17-1297.pdf
Using error detection to improve error correction. A neural sequence labeling model is used to find correctness probabilities for every token, which are then used to rerank possible correction candidates. The process consistently improves the performance of different correction systems.
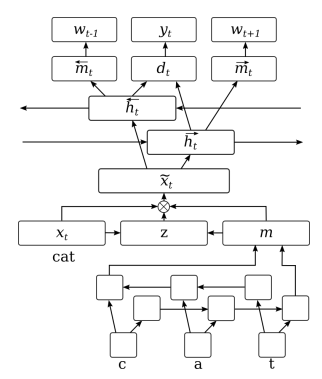
54. Artificial Error Generation with Machine Translation and Syntactic Patterns
Marek Rei, Mariano Felice, Zheng Yuan, Ted Briscoe. Cambridge. BEA 2017.
http://aclweb.org/anthology/W/W17/W17-5032.pdf
Investigating methods for generating artificial data in order to train better systems for detecting grammatical errors. The first approach uses regular machine translation, essentially translating from correct English to incorrect English. The second method uses local patterns with slots and POS tags to insert errors into new text.

55. Auxiliary Objectives for Neural Error Detection Models
Marek Rei, Helen Yannakoudakis. Cambridge. BEA 2017.
http://aclweb.org/anthology/W/W17/W17-5004.pdf
Investigating a range of auxiliary objectives for training a sequence labeling system for error detection. Automatically generated dependency relations and POS tags perform surprisingly well as gold labels for multi-task learning. Learning different objectives at the same time works better than doing them in sequence or switching.
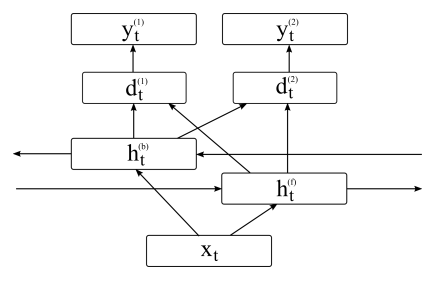
56. An Error-Oriented Approach to Word Embedding Pre-Training
Youmna Farag, Marek Rei, Ted Briscoe. Cambridge. BEA 2017.
http://aclweb.org/anthology/W/W17/W17-5016.pdf
Introduces a process for pre-training word embeddings with an objective that optimises them to distinguish between grammatical and ungrammatical sequences. This is then extended to also distinguish between correct and incorrect versions of the same sentence. The embeddings are then used in a network for essay scoring, improving performance compared to previous methods.

57. Detecting Off-topic Responses to Visual Prompts
Marek Rei. Cambridge. BEA 2017.
http://aclweb.org/anthology/W/W17/W17-5020.pdf
A neural architecture for detecting off-topic written responses, with respect to visual prompts. The text is composed with an LSTM and then used to condition the image representation. The two representations are then compared to calculate a confidence score for the text being written in response to the prompt image.

Thanks so much for the nice job!
Thank you so much…
Thank you for such a summary effort!
Good post
Hi, Marek. Awesome post. We are also waiting for the analysis of NLP publications this year! Keep it up.
Pingback:74 Summaries of Machine Learning and NLP Research - Marek Rei
Hi Marek,
Thank you so much for sharing your paper summaries so that we can learn from your rich experience. I’m reaching out to see if you are interested to post your reviews on a dedicated paper review platform at https://doublind.com. We are at our early stage and would like to invite you to be our seed users and any suggestions and thoughts are welcome!
Again thank you for all the awesome summaries!